


Negli ultimi anni l’accessibilità è passata dall’essere un tema “nice to have” a diventare un requisito concreto, normativo, etico e di qualità del prodotto, per chiunque sviluppi interfacce digitali. Eppure, nella maggior parte dei team, rimane ancora qualcosa che si aggiunge alla fine, un controllo da fare prima del rilascio, una checklist da spuntare.
Quando si costruisce un agente AI, questo approccio non funziona. Non perché le regole siano più severe, ma perché il problema è strutturalmente diverso.
Non stai più progettando pagine statiche o componenti UI con comportamenti prevedibili. Stai costruendo un’interfaccia conversazionale, dinamica, asincrona; un sistema in cui il contenuto nasce in tempo reale, cambia continuamente e viene generato da un modello che non ha idea di chi lo leggerà o con quali strumenti.
E questo introduce un problema nuovo: l’accessibilità non riguarda più solo il contenuto, ma il comportamento del sistema.
WCAG AA: il punto di partenza
Le linee guida WCAG restano il riferimento più solido disponibile. Ma nel contesto degli agenti AI, ciò che conta davvero non è conoscerle nel dettaglio, bensì capire quando un sistema smette di essere teoricamente accessibile e diventa realmente utilizzabile.
Quel punto coincide quasi sempre con il livello AA.
Non è il massimo raggiungibile (il livello AAA esiste e copre casi d’uso più specifici), ma è il livello in cui iniziano a sparire le barriere più comuni per chi usa tecnologie assistive: screen reader, navigazione da tastiera, ingrandimento del testo, software di riconoscimento vocale. Per questo, oggi, qualsiasi piattaforma digitale dovrebbe trattarlo come la propria baseline e non come un obiettivo ambizioso da raggiungere “quando c’è tempo”.
Il problema è che il livello AA è stato pensato per il web tradizionale: pagine, form, contenuti statici o semi-statici. Quando lo applichi a un’interfaccia conversazionale con generazione progressiva dei contenuti, ti accorgi rapidamente che alcune delle sue indicazioni vanno reinterpretate, e che altre lacune semplicemente non sono coperte.
Il layer invisibile: l’interfaccia della conversazione
Quando si parla di chatbot o assistenti AI, l’attenzione va quasi sempre sul modello: qualità delle risposte, gestione del contesto, capacità di ragionamento, velocità di risposta. Sono tutte cose importanti. Ma c’è un layer più basso, spesso completamente ignorato: l’interfaccia della conversazione stessa.
Una chat non è una pagina. È una sequenza di eventi che si aggiorna nel tempo, in modo asincrono, spesso in risposta ad azioni dell’utente ma non sempre. Se questa sequenza non è leggibile da uno screen reader in modo strutturato e coerente, la conversazione diventa incomprensibile, non parzialmente, ma del tutto. Non è un’esperienza degradata: è un’esperienza impossibile.
Ed è esattamente lì che si rompe tutto, e che la maggior parte delle implementazioni fallisce senza accorgersene.
Struttura semantica: modellare la conversazione
Il primo errore, e anche il più comune, è trattare i messaggi come semplice testo da visualizzare in una lista.
Ogni messaggio ha un ruolo e un contesto. Chi l’ha scritto? È una risposta a qualcosa di specifico? È ancora in elaborazione? Contiene elementi interattivi? Se questa informazione non è esplicitata nel markup, uno screen reader perde completamente la struttura della conversazione. Non sa chi sta parlando, non sa se c’è una risposta in arrivo, non sa come navigare tra i turni.
La soluzione è modellare la chat come una timeline semantica: usare pattern come role="log" per comunicare alle tecnologie assistive che il contenuto si evolve nel tempo, e strutturare i blocchi dei messaggi in modo da distinguere chiaramente l’autore, il tipo di contenuto e lo stato. Non stai solo strutturando il DOM per ragioni estetiche, stai definendo una grammatica della conversazione che gli strumenti assistivi possono interpretare.
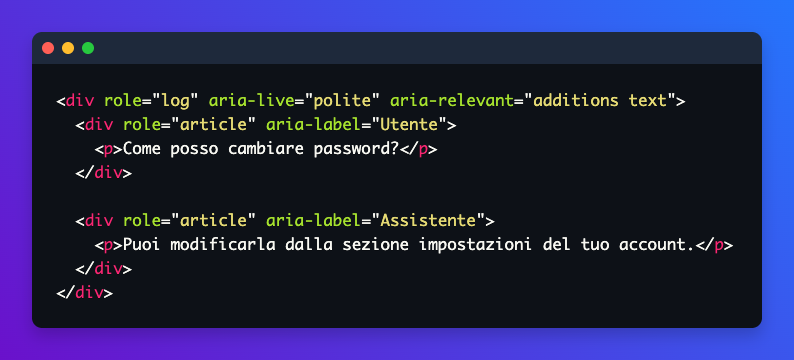
role="log" e messaggi distinti tramite role="article" e ARIA labelQuesto sembra un dettaglio tecnico, ma ha un impatto enorme sull’esperienza reale di chi usa uno screen reader: la differenza tra una conversazione che ha senso e una sequenza di testi senza contesto.
Streaming: il problema reale delle chat AI
La complessità esplode nel momento in cui introduci lo streaming.
Gli agenti AI non restituiscono una risposta completa, ma generano contenuto progressivamente.
Se ogni aggiornamento viene annunciato, l’esperienza diventa caotica. Se non viene annunciato, diventa invisibile.
Gli agenti AI non restituiscono una risposta completa e poi la mostrano. Generano contenuto progressivamente, token dopo token, e l’interfaccia si aggiorna in tempo reale per dare una sensazione di velocità e presenza. Dal punto di vista visivo, funziona benissimo. Dal punto di vista dell’accessibilità, crea un problema molto difficile da risolvere.
Se ogni singolo aggiornamento del testo viene annunciato dallo screen reader, l’esperienza diventa caotica: l’utente sente un flusso incomprensibile di frammenti di parole, interrotto continuamente. Se non viene annunciato nulla, la risposta è invisibile fino a quando non è completa e l’utente non sa se il sistema sta elaborando, si è bloccato, o ha già finito.
Non esiste una soluzione banale. Quello che funziona è separare il flusso visivo dal flusso accessibile: la UI si aggiorna liberamente per chi guarda lo schermo, mentre allo screen reader vengono inviati solo eventi significativi, come la notifica che una risposta è in elaborazione e l’annuncio della risposta completa una volta terminata la generazione.
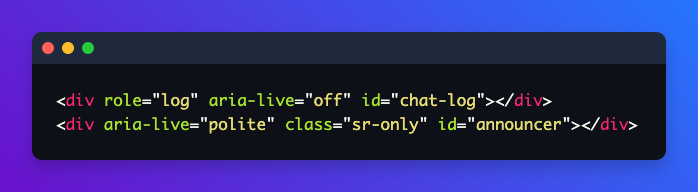
Questo è uno dei punti in cui l’accessibilità smette di essere un tema di markup e diventa un problema di orchestrazione del sistema: una decisione architetturale che deve essere presa a monte, non rattoppata a posteriori.
Navigazione: quando la chat diventa un sistema interattivo
Una chat moderna non è solo input e output testuale. Include suggerimenti contestuali, azioni rapide, contenuti interattivi come grafici, form incorporati, caroselli di opzioni, bottoni di conferma. Ogni elemento aggiuntivo è un potenziale punto di rottura per la navigazione da tastiera e per gli screen reader.
Se la navigazione viene lasciata al comportamento predefinito del browser, si ottiene un’interfaccia fragile e spesso del tutto inutilizzabile senza mouse. L’ordine del focus può essere scorretto, gli elementi interattivi possono non essere raggiungibili, le azioni potrebbero non avere etichette comprensibili.
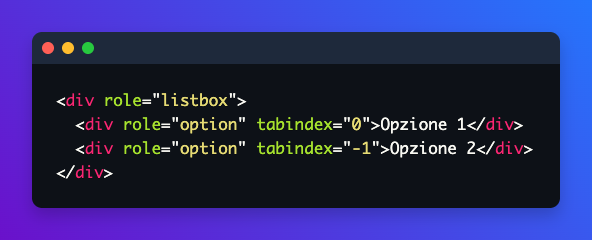
Serve invece gestire esplicitamente focus e pattern di interazione: componenti con ruoli ARIA corretti e coerenti, logica di navigazione strutturata che accompagni l’utente attraverso la conversazione, comportamento prevedibile tra sessioni diverse. La domanda da porsi non è “l’utente riesce a cliccare?” ma “l’utente riesce ad attraversare l’intera conversazione, quindi messaggi, azioni, contenuti, senza usare il mouse, senza vedere lo schermo?”
Rendering: il punto in cui l’AI rompe l’accessibilità
Con i contenuti generati dinamicamente, il problema si sposta in modo radicale rispetto al web tradizionale.
In un sito classico controlli il markup. Sai esattamente cosa verrà renderizzato, puoi strutturarlo a priori, puoi testarlo in modo statico. Con gli agenti AI controlli solo il processo di generazione e non il risultato. Il modello può produrre liste, tabelle, blocchi di codice, intestazioni, citazioni, link. Ma non ha alcuna consapevolezza di come questi elementi verranno presentati, né di chi li leggerà.
Questo significa che l’accessibilità non può stare nel contenuto prodotto dal modello ma deve stare nel renderer.
Se l’AI produce una lista numerata e tu la mostri come testo piano, hai perso la struttura. Se produce un blocco di codice e non lo etichetti correttamente, hai reso incomprensibile qualcosa che richiede contesto per essere capito. Se genera una tabella e il renderer non applica i ruoli semantici corretti, hai creato una barriera invisibile per chiunque usi uno screen reader.
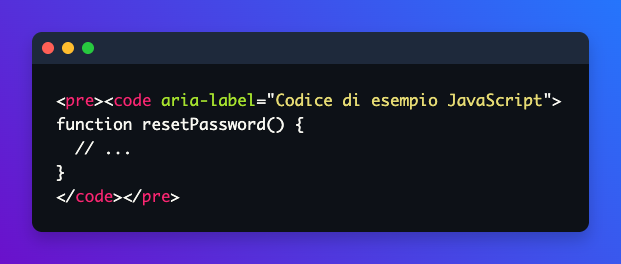
Il renderer non è un componente di visualizzazione. È il sistema che garantisce che qualsiasi contenuto, generato in qualsiasi modo, arrivi all’utente in modo strutturato, semantico e navigabile. Qui il valore non è visivo. È semantico.
Come implementiamo l’accessibilità in Userbot
Quando costruisci una piattaforma di agenti AI, l’accessibilità non può essere trattata come un controllo finale. Deve essere incorporata nei layer del sistema.
Il primo livello è quello della conversazione. I messaggi non sono stringhe, ma oggetti strutturati che includono ruolo, tipo e metadati. Questo permette al frontend di sapere sempre come renderizzare correttamente un contenuto, indipendentemente da come è stato generato.
Il secondo livello è il rendering. Nessun output AI viene mostrato direttamente nell’interfaccia. Tutto passa attraverso un sistema di rendering centralizzato che converte il contenuto in HTML semantico, applica ruoli ARIA appropriati e garantisce che ogni elemento (testo, tabella, lista, codice, azione) sia navigabile e comprensibile.
Il terzo livello è quello dell’interazione. Qui gestiamo esplicitamente focus, navigazione da tastiera e annunci. In particolare, separiamo sempre lo streaming visivo dagli eventi annunciati agli screen reader, evitando sia il rumore continuo che la perdita di informazione.
Infine c’è il testing. Non basta che l’interfaccia “sembri” accessibile. Deve funzionare realmente in condizioni non visive. Questo significa usare screen reader, navigare solo da tastiera e verificare che la conversazione resti comprensibile anche senza vedere lo schermo. Perché un’interfaccia che sembra accessibile ma non funziona senza schermo, semplicemente, non è accessibile.
Conclusione
Nel mondo degli agenti AI, l’accessibilità non è più una proprietà del layout. È una proprietà della conversazione.
Riguarda come un sistema viene costruito, aggiornato e attraversato nel tempo e non solo come appare a schermo. Riguarda le decisioni architetturali prese mesi prima del rilascio, non i fix cosmetici dell’ultima settimana. Il livello WCAG AA è il punto di partenza giusto e irrinunciabile, ma la vera sfida è progettare sistemi che restino pienamente utilizzabili anche quando l’interfaccia non è visibile, quando il contenuto cambia in tempo reale, quando l’utente non usa un mouse.
Perchè è esattamente lì, nell’uso reale, che si misura la qualità vera di un’architettura.




