


Quando un agente AI fa qualcosa di sbagliato, risponde male o non esegue un’azione che dovrebbe eseguire, qual è la prima cosa che fai?
Se la risposta è “rileggo il prompt e sperimento”, sei in buona compagnia. Ma sei anche in un posto che, a lungo andare, non scala.
Il problema non è la risposta sbagliata in sé. Il problema è che non sai perché è successa. E se non sai perché è successa, non puoi correggere in modo affidabile: puoi solo sperare che la prossima versione funzioni meglio. Questo va bene per un prototipo. Non va bene per un sistema in produzione.
L’osservabilità e il debug degli agenti AI sono esattamente la risposta a questo problema: la capacità di aprire quella scatola nera e leggere quello che c’è dentro. In questo articolo vediamo perché è più difficile di quanto sembri, quali sono i livelli del problema, e come Userbot 3.0 li affronta in modo concreto con strumenti pensati per sviluppatori, team operations e auditor.
Perché il debug degli agenti AI non funziona come il debug tradizionale
Con i vecchi chatbot a flusso fisso la vita era più semplice, almeno su questo fronte. L’utente diceva X, il bot seguiva il ramo Y, qualcosa andava storto nel ramo Y. Trovavi il ramo, correggevi il testo, fine. La logica era tutta lì, visibile, percorribile passo dopo passo.
Gli agenti AI funzionano in modo fondamentalmente diverso. Non seguono un percorso predefinito: prendono decisioni. Valutano il contesto della conversazione, scelgono quale tool chiamare, stabiliscono se hanno abbastanza informazioni per rispondere o se devono raccoglierne altre, decidono quando passare la mano a un operatore umano. Ogni interazione è il risultato di una catena di ragionamenti che, nella maggior parte dei sistemi, rimane completamente invisibile.
Quello che vedi dall’esterno è solo l’inizio e la fine: l’input dell’utente e l’output dell’agente. Tutto ciò che è successo nel mezzo (quale routing è stato scelto, quali fonti sono state consultate, quali tool sono stati invocati, quali variabili erano disponibili in quel momento) rimane opaco. È quella che si chiama “black box” dell’AI, e finché resta tale il debug degli agenti AI è impossibile da fare in modo sistematico. Si va avanti per tentativi, il che non è un metodo: è una speranza.
Cos’è l’osservabilità degli agenti AI, e perché è più difficile di quanto sembri
Nel software tradizionale, l’osservabilità è un concetto consolidato: è la capacità di capire lo stato interno di un sistema a partire dai suoi output, attraverso metriche, log e trace. È una disciplina matura, con strumenti maturi.
Nei sistemi agentici il concetto di partenza è lo stesso, ma la natura del problema è diversa. Non stai tracciando l’esecuzione di codice deterministico, dove lo stesso input produce sempre lo stesso output. Stai tracciando il ragionamento di un sistema probabilistico, che può prendere strade diverse a seconda di come è formulata la domanda, di quale versione del modello è in uso, di quali informazioni erano disponibili nel knowledge base in quel momento.
Questo rende l’osservabilità degli agenti AI sia più difficile che più necessaria rispetto al software classico. Più difficile perché non basta loggare “l’agente ha risposto Y a X”: devi documentare perché ha risposto Y, quale percorso ha selezionato, su quali fonti si è basato, quali tool ha chiamato con quali parametri, e come tutto questo ha influenzato il risultato finale. Più necessaria perché senza questa visibilità qualsiasi ottimizzazione è un’operazione nel buio: puoi modificare il prompt e vedere che le cose “sembrano andare meglio”, senza poter sapere se hai risolto il problema o se lo stai solo spostando altrove.
I tre livelli del problema
Quando si parla di monitoraggio degli agenti AI, vale la pena distinguere tre livelli diversi, perché richiedono risposte diverse.
Il primo è il livello della conversazione: cosa ha detto l’utente, cosa ha risposto l’agente. È il più visibile, ed è il livello su cui si concentra di solito il feedback degli utenti finali. Il problema è che da solo racconta pochissimo sulle cause. Una risposta sbagliata può dipendere da un routing errato, da una fonte di conoscenza incompleta, da un tool che ha restituito un errore gestito male, da un prompt che non copre un caso limite. Senza andare più in profondità, questi scenari sono indistinguibili.
Il secondo è il livello dell’esecuzione: quali componenti sono stati attivati, in quale ordine, con quali input e output. Qui troviamo il router (quale percorso ha scelto e perché), il retriever (quali documenti ha recuperato), i tool chiamati con i loro parametri e le loro risposte, le condizioni valutate, le variabili aggiornate. È il livello che permette di fare debug reale: se il router ha instradato male una richiesta puoi vederlo, se il retriever ha recuperato documenti poco pertinenti puoi intervenire sulla strategia, se un tool ha restituito un errore puoi capire se è un problema di schema, di timeout o di parametri.
Il terzo è il livello del ragionamento: perché l’agente ha preso quella decisione? Quali alternative aveva valutato? Su quali criteri si è basato? Non è una curiosità tecnica. È ciò che permette di verificare se il comportamento dell’agente è davvero allineato con le intenzioni di chi lo ha progettato, e di dimostrarlo quando serve, anche in contesti regolamentati.
Come funziona in pratica: i badge delle sessioni in Userbot
Passiamo al concreto. Come si trasforma tutto questo in qualcosa di utilizzabile ogni giorno?
In Userbot 3.0, il punto di accesso all’osservabilità è la sezione Conversazioni. Ogni sessione, di test o di produzione, è navigabile nel dettaglio: non una semplice trascrizione di messaggi, ma una mappa di tutti i blocchi che sono stati attraversati durante quell’interazione, ognuno con il proprio badge informativo.
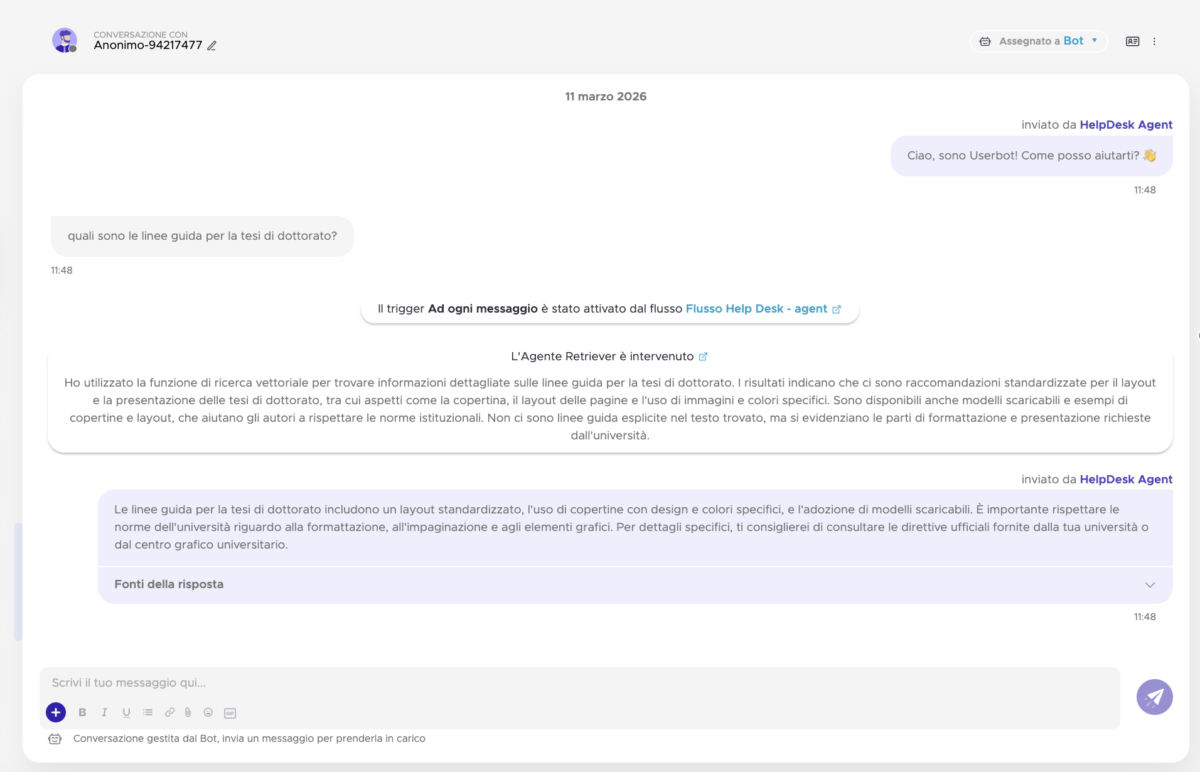
L’idea alla base è semplice: ogni blocco del flusso, nel momento in cui viene eseguito, produce una traccia. Quella traccia viene resa leggibile come badge e resa accessibile direttamente dalla sessione. Il risultato è che puoi ripercorrere un’interazione passo dopo passo, dall’input iniziale fino all’ultima azione eseguita, e capire esattamente cosa è successo in ogni punto. Non devi ricostruire niente: è tutto lì.
Blocchi non agentici: codice, HTTP, condizioni
Anche i blocchi “tradizionali”, quelli senza LLM, hanno il loro badge, e spesso è già sufficiente per risolvere il problema.


Un blocco di codice JavaScript mostra il codice che è stato eseguito, l’esito e, se qualcosa è andato storto, il messaggio di errore con il dettaglio necessario per capire dove e perché si è rotto.

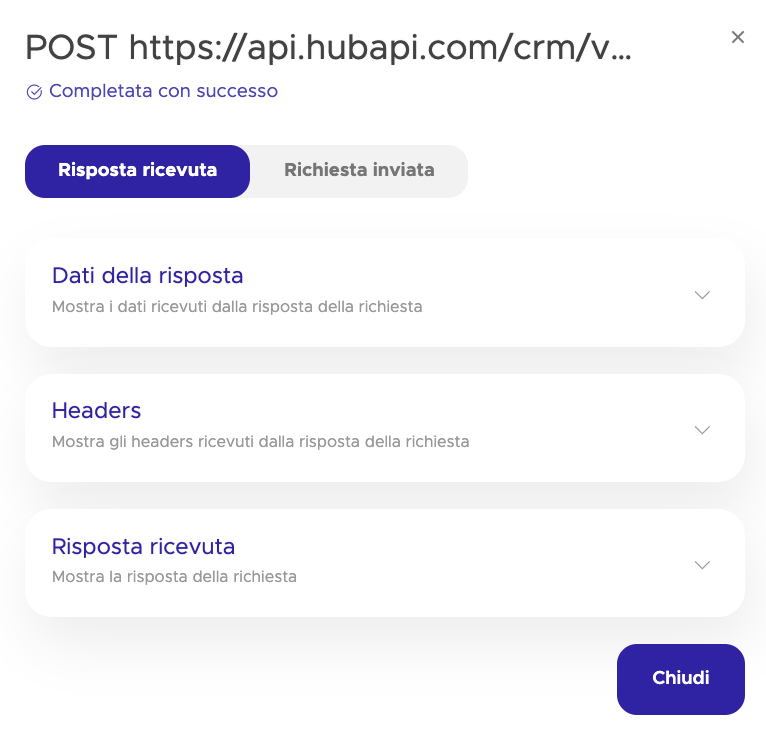
Un blocco di request HTTP ti mostra l’input della chiamata, la risposta ricevuta dal sistema esterno e quali valori sono stati poi salvati nelle variabili del flusso, utile per verificare se l’integrazione ha restituito quello che ti aspettavi e se i dati sono stati mappati nel modo corretto.
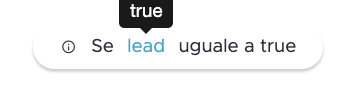
Un blocco di verifica condizione ti mostra cosa è stato valutato: il valore della variabile presa in esame, la condizione applicata, il ramo che è stato scelto.
In tutti questi casi, e per qualsiasi tipo di blocco, il badge fa una cosa sola, ma la fa bene: trasforma ogni blocco da elemento opaco a elemento leggibile. Non devi ipotizzare cosa ha fatto, lo vedi.
Blocchi agentici: prompt, parametri e memoria
Nei blocchi che coinvolgono un agente AI il badge si arricchisce ulteriormente.
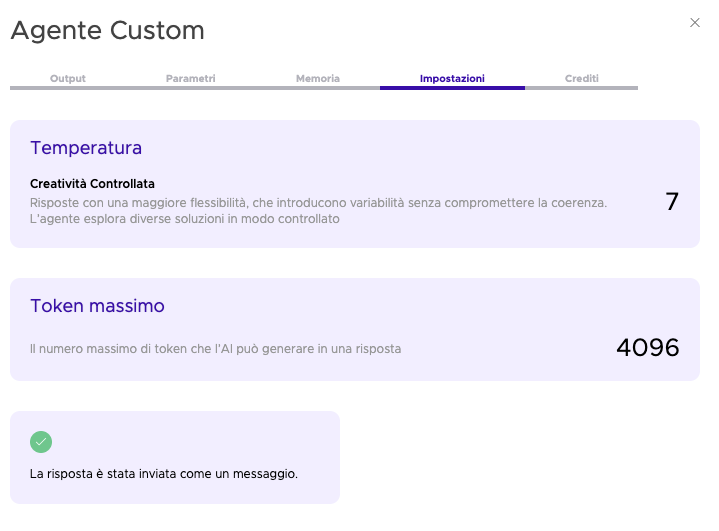
Per ogni agente trovi esposti i parametri di configurazione e di chiamata: il prompt inserito, il modello selezionato, la temperatura, i max token. Trovi la memoria attivata in quel momento (conversazionale o profonda) così puoi vedere esattamente quale contesto era disponibile per l’agente quando ha elaborato la risposta. Se la risposta è sembrata “scollata” dalla conversazione precedente, spesso è perché la memoria non era configurata come pensavi.
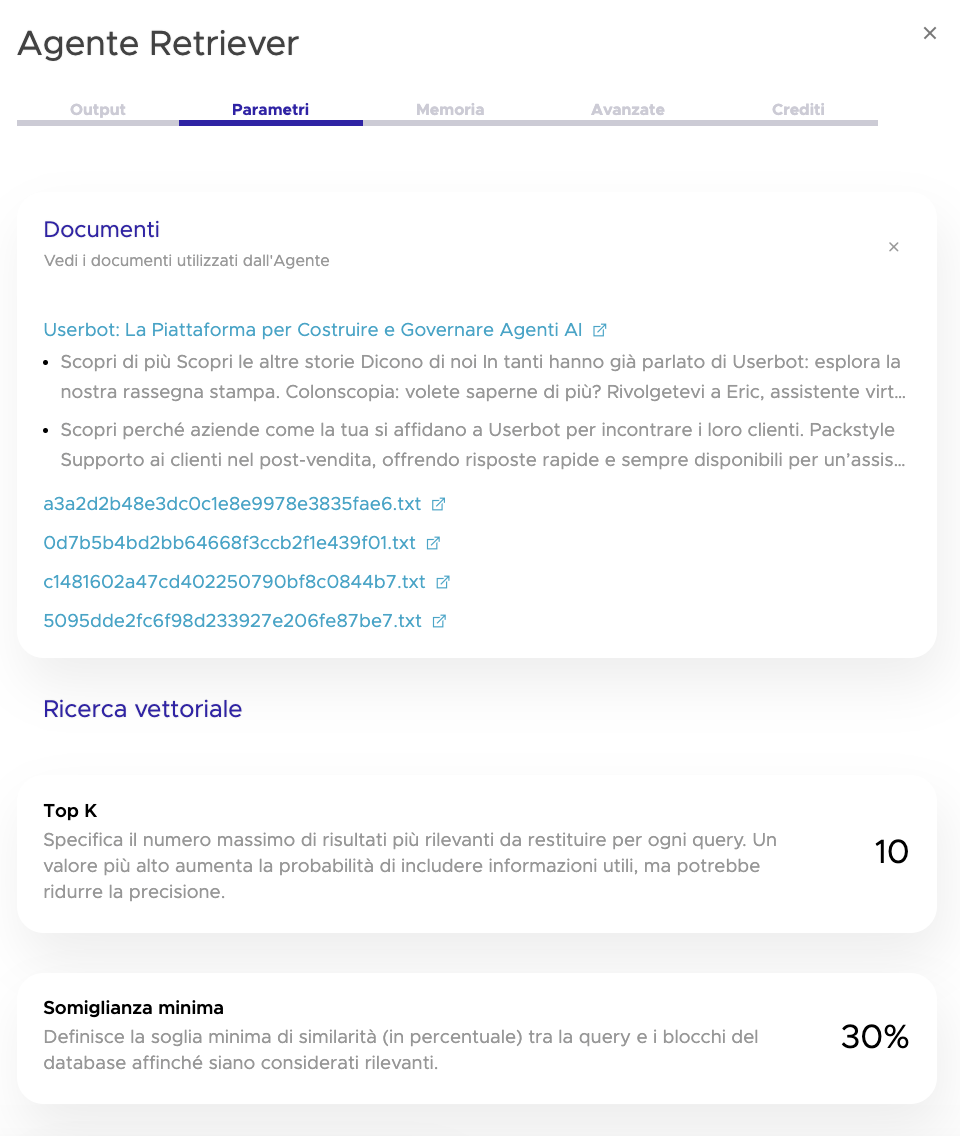
Nel caso del Retriever Agent trovi anche i chunk estratti dalle fonti e utilizzati per costruire la risposta. Non solo “ha consultato la knowledge base”, ma quali porzioni specifiche di quali documenti sono state recuperate. Quando un retriever risponde in modo impreciso o fuori tema, questa è la prima cosa da guardare: spesso il problema non è nel prompt, ma nella qualità dei chunk o nella pertinenza delle fonti.
Il Thought of Process: la cosa più importante
La sezione più preziosa del badge agentico si chiama Thought of Process, ed è quella che cambia davvero il modo di lavorare con gli agenti AI.
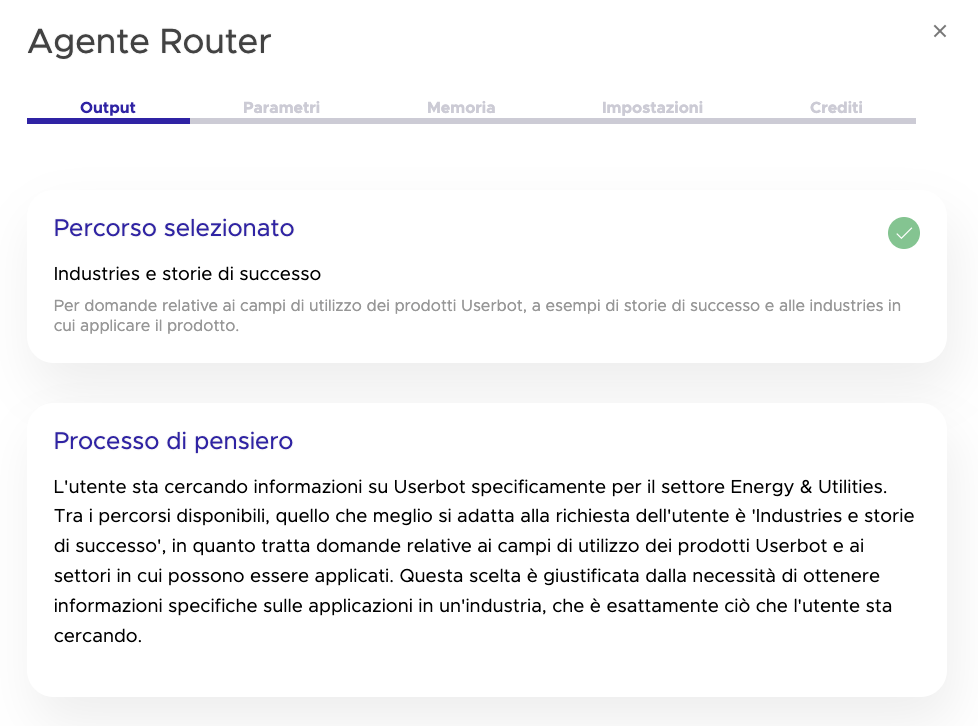
Non è un log tecnico nel senso tradizionale. È la spiegazione che l’agente produce su se stesso: perché ha risposto in quel modo, quale ragionamento ha seguito, quali elementi del contesto o del prompt hanno guidato la sua decisione. In sostanza, l’agente ti racconta cosa ha pensato.
Immagina di ricevere una risposta inattesa da un agente. Prima del Thought of Process, il processo di debug era: formulare un’ipotesi su dove il prompt poteva essere ambiguo, fare una modifica, ritestare, sperare. Un ciclo lento, costoso, e spesso frustrante. Con il Thought of Process, salti quella fase: l’agente ti dice direttamente dove il prompt non era chiaro, cosa aveva capito e perché ha preso quella direzione.
È anche lo strumento che permette di distinguere due tipi di problema che all’esterno sembrano identici ma richiedono interventi completamente diversi: un agente che ha sbagliato perché il prompt era incompleto, e un agente che ha sbagliato perché le informazioni disponibili erano insufficienti o errate. Nel primo caso lavori sul prompt, nel secondo lavori sulle fonti. Senza il Thought of Process, spesso non sai da dove iniziare.
I tool: sai sempre se sono stati chiamati e come è andata
Per i blocchi che coinvolgono tool, chiamate ad API esterne, integrazioni con CRM, ERP, sistemi di ticketing, il badge risponde sempre alle due domande fondamentali: il tool è stato invocato? La chiamata è andata a buon fine?
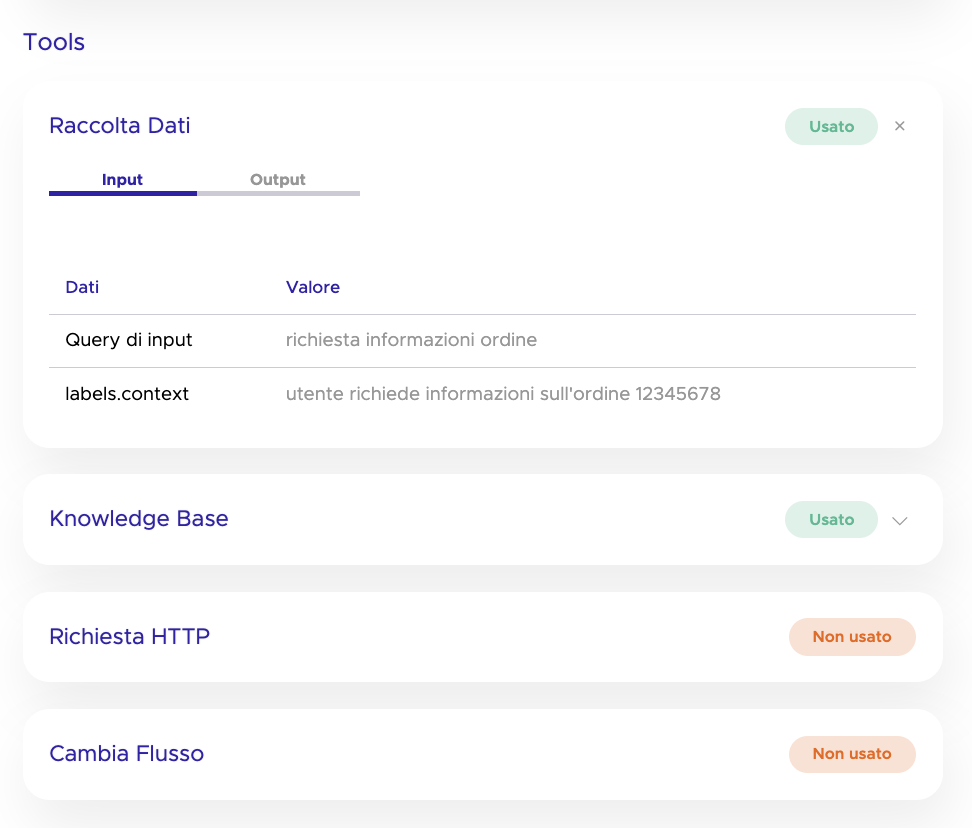
Sembra una cosa ovvia, ma in pratica risolve uno dei pattern di errore più frustranti nel debug degli agenti AI. Quando un agente “non fa niente”, non apre il ticket, non aggiorna il record nel CRM, non invia la notifica, la prima cosa da capire è se il problema è nell’agente o nell’integrazione. Il tool è stato chiamato? Se sì, cosa ha restituito? Se no, perché no? Con il badge questa informazione è sempre lì, senza bisogno di andare a cercare nei log di sistema o fare debug lato API.
Sapere se il tool è stato chiamato con successo o meno ti dice immediatamente dove guardare dopo. E questo, in pratica, può fare la differenza tra mezz’ora di debug e mezza giornata.
L’osservabilità non si aggiunge dopo: va progettata dall’inizio
Una cosa che abbiamo imparato costruendo sistemi agentici in produzione è che l’osservabilità non è una feature che si aggiunge a sistema pronto. È una proprietà che va progettata dall’inizio, nell’architettura. Se la pensi come un’aggiunta successiva, arrivi tardi: nel momento in cui ne hai davvero bisogno, le informazioni non ci sono.
Questo significa che ogni componente (router, retriever, tool executor, agente di condizione) deve produrre output strutturati e tracciabili. Il sistema deve mantenere un contesto di esecuzione navigabile attraverso tutti i passaggi di un’interazione. E le informazioni esposte devono essere progettate per rispondere a domande specifiche, non solo per “registrare eventi”.
In Userbot 3.0, questo principio ha guidato la progettazione della sezione Conversazioni e del sistema di badge fin dall’inizio. L’obiettivo non era costruire uno strumento di debug riservato agli sviluppatori, ma rendere il ragionamento dell’AI leggibile e verificabile per chiunque abbia bisogno di capire o migliorare il comportamento di un agente: un engineer, un team operations, un auditor che deve dimostrare conformità a un processo.
Nella pratica, questo significa che quando qualcosa non funziona non si parte da zero. Si apre la sessione, si scorrono i blocchi attraversati, si apre il badge del punto in cui il comportamento era inatteso, si legge il Thought of Process. In molti casi la causa è immediatamente visibile: un parametro configurato male, una memoria che non era attiva, un chunk poco pertinente recuperato dal retriever, un tool che ha restituito un errore non gestito. Si interviene in modo chirurgico, si ritesta.
Il legame tra osservabilità e stabilità nel tempo
C’è un ultimo aspetto che vale la pena nominare, perché tende ad essere sottovalutato nelle fasi iniziali di un progetto agentico, e diventa evidente solo più avanti.
L’osservabilità degli agenti AI non serve solo a correggere gli errori di oggi. Serve a mantenere il sistema stabile nel tempo, anche quando i componenti sottostanti cambiano, e cambieranno, perché è la natura di questo campo. I modelli LLM vengono aggiornati dai provider. Le fonti di conoscenza evolvono. Le policy aziendali cambiano. In un sistema ben osservabile puoi introdurre questi cambiamenti in modo controllato: misuri il comportamento prima, introduci la modifica, verifichi che il comportamento resti allineato con le aspettative.
In un sistema opaco, ogni cambiamento è un rischio che scopri solo dopo. Non sai cosa hai rotto finché qualcuno non se ne accorge, che in produzione di solito significa un utente insoddisfatto o un processo che si è interrotto.
Per questo in Userbot 3.0 l’architettura separa nettamente i layer che devono restare stabili (policy, guardrail, contratti delle API) da quelli che possono variare, come il modello LLM utilizzato per un determinato task. Quando questi layer sono separati, la visibilità su ciascuno diventa uno strumento di governance attivo: ti permette di cambiare quello che vuoi cambiare senza toccare quello che vuoi mantenere stabile.
In fondo, l’osservabilità è la condizione che rende possibile la fiducia verificabile nell’AI. Non la fiducia cieca nel fatto che “di solito funziona bene”, ma quella basata su dati, tracce e misure concrete. Quella che serve quando gli agenti AI entrano nei processi davvero critici, dove sbagliare ha un costo reale.
Con Userbot 3.0, l’AI non è più un atto di fede. È un processo che puoi osservare, misurare e migliorare nel tempo.
possiamo aiutarti?
il nostro team è a tua disposizione.




