


Leggere un PDF
Quando si parla di document processing in un contesto AI, la maggior parte delle persone pensa a una semplice estrazione di testo. La realtà è molto diversa: i documenti contengono tabelle sotto forma di immagini, grafici, diagrammi, loghi decorativi e layout complessi che un parser testuale non può nemmeno vedere.
In questo articolo raccontiamo come abbiamo costruito una pipeline di document processing che combina OCR, modelli vision e post-processing intelligente, e soprattutto dove abbiamo incontrato i limiti reali di queste tecnologie.
L’architettura: estrazione e strutturazione del documento
Il cuore della nostra pipeline è un sistema di componenti OCR e di layout analysis che trasforma i PDF in una rappresentazione più strutturata, separando testo, immagini e tabelle. Questo processo richiede risorse computazionali dedicate, ma è il presupposto necessario per integrare effettivamente immagini e tabelle nelle risposte dei nostri Agenti AI.
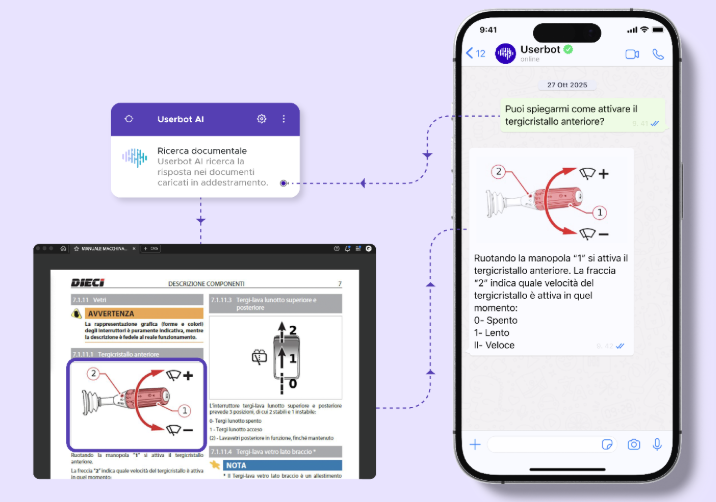
Vediamo insieme come le cose si fanno interessanti.
Il problema delle immagini: non tutto ciò che è immagine è utile
Durante l’estrazione, vengono individuate tutte le immagini dal PDF. Ma in un documento tipico, la maggior parte delle “immagini” sono:
- indicatori di layout (linee, separatori)
- icone decorative
- loghi ripetuti in header/footer
- artefatti grafici senza valore informativo
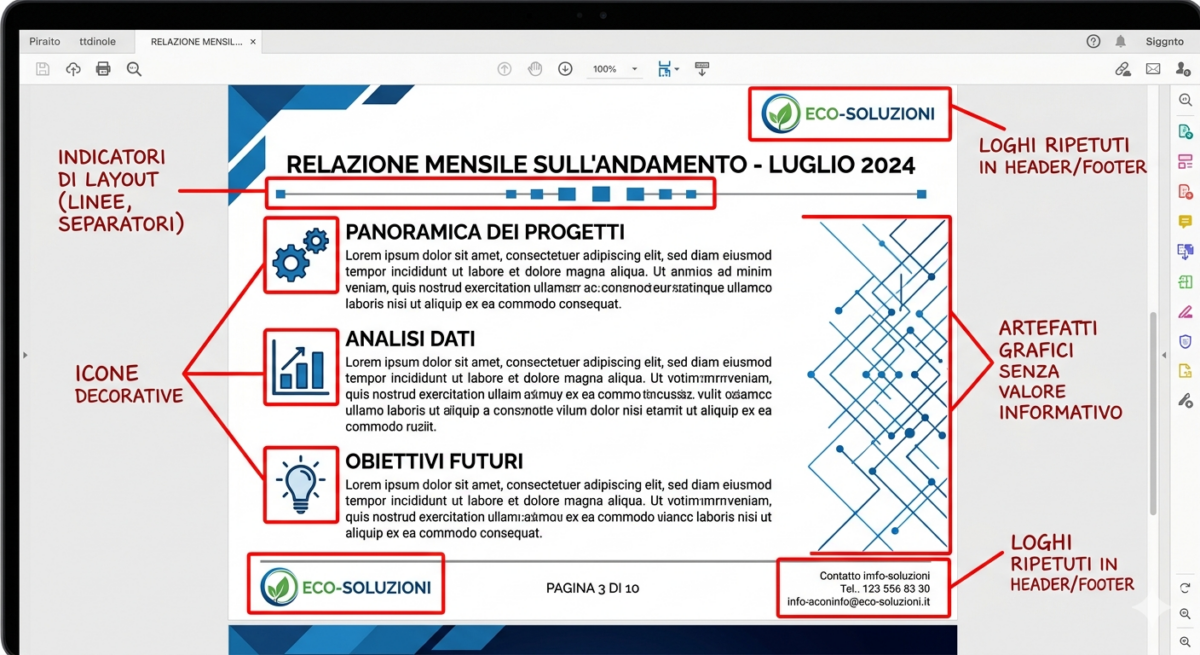
Tenere tutte queste immagini ha un costo: occupano spazio, confondono i modelli di embedding downstream, e rallentano il processing. Passare ogni immagine al modello di embedding così com’è, quindi, non è una strategia sostenibile: è costoso, lento e introduce rumore nel knowledge base. Avevamo bisogno di un sistema che capisse per ogni immagine, se vale la pena tenerla, e se sì, come trattarla.
La soluzione: filtro visuale intelligente
Abbiamo costruito un sistema di post-processing che usa modelli multimodali per classificare ogni immagine estratta. Il modello riceve l’immagine e il testo circostante, e deve rispondere a tre domande precise:
1. È un artefatto di layout? Questa domanda serve a scartare subito tutto ciò che non porta informazione reale: linee divisorie, frecce decorative, loghi ripetuti in ogni pagina, icone di navigazione. Un’immagine classificata come artefatto viene eliminata prima ancora di generare una descrizione.
2. È una tabella? Questa classificazione innesca un percorso di trattamento completamente diverso. Le tabelle non possono essere gestite come immagini generiche: il loro valore sta nella struttura, nelle relazioni tra righe e colonne, nei dati che contengono. Se il modello riconosce una tabella, quella immagine non viene descritta a parole, bensì il suo contenuto viene ricostruito in modo strutturato.
3. Qual è la descrizione? Per tutte le immagini che non sono artefatti né tabelle – grafici, diagrammi, screenshot, infografiche – il modello genera un breve riassunto del contenuto visivo. Questa descrizione diventa il punto di accesso all’immagine per i sistemi di retrieval. La qualità di questa risposta determina direttamente la qualità del retrieval downstream.
Il contesto è tutto
Un’immagine senza contesto è ambigua. Un grafico a torta potrebbe essere irrilevante o fondamentale, dipende da cosa dice il testo intorno. Per questo, per ogni immagine il modello vision riceve anche il testo che la circonda nel documento, usato come contesto per produrre una descrizione più accurata e coerente con il contenuto complessivo.
Questo approccio ha un side-effect positivo: la descrizione generata usa la stessa lingua del documento, perché il contesto “ancora” il modello al linguaggio corretto.
Tuttavia non c’è nessuna garanzia che la posizione dell’immagine sia effettivamente vicino al testo a cui fa riferimento e questo avrà effetti negativi downstream.
Tabelle: il caso più insidioso
Le tabelle sono il nemico numero uno dell’OCR tradizionale. I sistemi di layout detection le riconoscono come immagini, ma il testo al loro interno viene perso. La nostra soluzione è un secondo passaggio in cui un modello vision ricostruisce la struttura della tabella in formato testuale strutturato, che viene poi reinserito nel documento elaborato.
Questo è un game-changer per la qualità del testo finale: le tabelle diventano ricercabili, embeddable e comprensibili da un LLM.
Tuttavia tabelle molto complesse (merge di celle, tabelle nested, layout non standard, o una tabella composta da immagini) rimangono problematiche. Il modello a volte inventa dati o perde l’allineamento delle colonne. Non c’è una soluzione perfetta, solo mitigazione.
Embeddings: come si “vettorializza” un’immagine
Le immagini ritenute valide vengono salvate con la loro descrizione testuale.
Perché è importante? I modelli di embedding testuale che usiamo per il RAG non possono “vedere” le immagini, ma possono leggere le descrizioni associate. La descrizione generata dal modello vision, insieme alla sua posizione all’interno del testo, diventano il ponte tra mondo visuale e mondo vettoriale.
La qualità dell’embedding, quindi, dipende interamente dalla qualità della descrizione. Una descrizione generica (“un grafico”) è quasi inutile. Una descrizione ricca (“grafico a barre che confronta revenue Q1 vs Q2, mostrando un incremento del 23%”) è oro per il retrieval.
I limiti reali che abbiamo incontrato
1. Tempi di processing
Il processing di documenti complessi richiede tempo: l’estrazione, la classificazione visuale e la ricostruzione delle tabelle sono fasi sequenziali, ognuna con il proprio peso. Per documenti lunghi o ricchi di immagini, il tempo totale può essere significativo.
2. Errori del modello vision
I modelli multimodali non sono infallibili: a volte classificano come “invalide” immagini che contengono informazioni utili, altre creano descrizioni che possono essere troppo generiche o contenere allucinazioni, altre ancora le tabelle ricostruite possono avere errori di allineamento.
Insomma, come tutte le volte che si usa un modello AI, i risultati non possono per loro natura essere deterministici ed avere il 100% di precisione e accuratezza.
3. La catena di errori
Ogni step della pipeline può introdurre errori che si propagano: se l’estrazione del layout non è precisa, le immagini risultano tagliate male; se il filtro visuale scarta un’immagine importante, l’informazione viene persa; se la descrizione è inaccurata, gli embedding sono di bassa qualità e il retrieval peggiora. La qualità finale è il prodotto di tutte le probabilità di successo di ogni step.
4. Scalabilità
Il processing di documenti complessi richiede un equilibrio tra qualità, performance e sostenibilità operativa. Non è un servizio che si può semplicemente “tenere sempre acceso”: le risorse computazionali devono essere allocate in modo intelligente, bilanciando velocità di risposta ed efficienza complessiva.
Cosa abbiamo imparato
L’OCR da solo non basta: servono modelli vision per capire cosa c’è nelle immagini e se vale la pena tenerle.
Il contesto salva la qualità: passare il testo circostante al modello vision migliora drasticamente le descrizioni. Ma attenzione: un documento non progettato per essere indicizzato semanticamente produrrà comunque risultati limitati.
Le tabelle richiedono un trattamento speciale: non puoi trattarle come immagini normali né come testo OCR. Serve un passaggio dedicato.
Conclusione
Leggere immagini nei documenti nel 2026 è ancora un problema aperto. Non esiste una soluzione end-to-end che funzioni sempre. Abbiamo sviluppato un approccio che combina estrazione documentale, analisi visuale e post-processing intelligente, con l’obiettivo di rendere i contenuti più accessibili ai sistemi AI; consapevoli che ogni componente ha i propri limiti.
Il consiglio più onesto che posso dare: non bisogna cercare di adattare i docuemnti esistenti al retrieval, ma bisogna produrre documenti pensati din dall’inizio per la ricerca semantica. La nostra soluzione è un buon punto di partenza, per permettere di utilizzare documenti pre-esistenti, ma non può essere il punto di arrivo.
possiamo aiutarti?
il nostro team è a tua disposizione.




