



Perché la differenza tra un agente che funziona e uno che delude spesso non sta nel modello scelto, ma nelle parole usate per istruirlo.
C’è una scena che chi lavora con agenti AI riconosce immediatamente.
L’agente è stato configurato con cura, testato in decine di scenari, approvato. Va in produzione.
E poi, in un caso che nessuno aveva previsto esplicitamente, non un caso strano, anzi, un caso normalissimo, fa qualcosa di sbagliato.
Non di molto.
Ma abbastanza da creare un problema.
La reazione tipica è cercare il bug nel codice, nel modello, nell’integrazione. Raramente si guarda dove il problema spesso davvero si nasconde: nelle istruzioni. Nel linguaggio con cui è stato detto all’agente cosa fare.
Quello che segue non è un articolo di tecnologia in senso stretto. È un articolo su come funziona davvero la comunicazione con un Large Language Model e su perché, padroneggiare questa differenza, è una delle leve più sottovalutate per chi commissiona o supervisiona un progetto AI.
Partiamo dall’inizio, e cioè da cosa distingue un LLM da un essere umano quando legge un testo.
Gli LLM leggono le parole. Gli umani leggono le intenzioni.
Quando un collega riceve una procedura scritta male, la interpreta. Usa il contesto, l’esperienza, il buon senso.
Se manca un’indicazione, suppone quella più ragionevole. Se una regola non copre un caso specifico, estrapola l’intenzione di chi l’ha scritta.
Un LLM non fa niente di tutto questo; o meglio, lo fa in modo molto meno affidabile di quanto si pensi. I modelli linguistici hanno sviluppato una capacità impressionante di generare risposte pertinenti e coerenti. Ma non ragionano per intenzioni: ragionano per pattern linguistici. La differenza, in produzione, si vede.
Un esempio concreto:
Un agente per il supporto clienti di una società di noleggio viene istruito a “gestire le richieste di modifica prenotazione”. Arriva un cliente che vuole cancellare e ri-prenotare per date diverse. L’agente non gestisce la richiesta perché tecnicamente non è una modifica, ma è una cancellazione seguita da una nuova prenotazione. Un operatore umano avrebbe capito l’intenzione in mezzo secondo. L’agente no, perché quella casistica non era scritta da nessuna parte.
Questo è il punto di partenza da cui discendono tutti gli altri problemi che vedremo. Non è una questione di intelligenza del modello: è una questione strutturale, legata a come i LLM elaborano il linguaggio. Tenerlo a mente cambia il modo in cui si scrivono le istruzioni e, di conseguenza, il modo in cui si comporta l’agente.
I modelli linguistici non condividono il nostro bagaglio implicito di esperienza e cultura. Ogni inferenza che per noi è ovvia, per loro deve essere scritta.
Il peso delle parole prescrittive: “must” vs “should”
Se il problema di fondo è che i modelli leggono il testo alla lettera, la prima conseguenza pratica riguarda il tipo di istruzioni che si danno. In particolare, la differenza tra un’indicazione prescrittiva, qualcosa che l’agente deve fare senza eccezioni, e una raccomandazione, che può essere ignorata in presenza di ragioni sufficienti.
Dire a un agente “usa sempre e solo la lingua italiana” è diverso da dire “rispondi in italiano”. Nel secondo caso, il modello ha una via d’uscita implicita. Se l’utente scrive in inglese, se il contesto è ambiguo, se riporta una fonte citata in francese, il modello potrebbe scegliere di non seguire quell’indicazione, perché l’istruzione stessa glielo consentiva.
Nella pratica quotidiana, chi scrive le istruzioni di un agente tende a usare un linguaggio naturale usando termini come: “dovresti”, “di norma”, “cerca di”, perché è il modo in cui comunichiamo tra esseri umani, dove il contesto colma le lacune. Con un LLM, quelle sfumature diventano varchi operativi.
Un esempio concreto:
Un agente configurato per “preferibilmente non citare i competitor” discuterà di competitor non appena un utente lo solleciterà direttamente: non gli era stato proibito, solo sconsigliato.
Le istruzioni condizionali: quando “o” non basta
Un’altra conseguenza diretta del modo in cui i modelli leggono il testo riguarda le istruzioni condizionali: quelle del tipo “se accade X, fai Y”. Sono le più comuni, e anche quelle in cui gli errori di formulazione sono più difficili da intercettare prima di andare in produzione.
Un esempio concreto:
Un agente per la gestione di richieste HR viene istruito a trasferire la conversazione a un operatore umano “se l’utente esprime insoddisfazione o richiede informazioni riservate”. In test, funziona. Poi in produzione arriva un utente che è chiaramente frustrato e, nello stesso messaggio, chiede dati sensibili sul proprio contratto. L’agente non trasferisce. Perché l’istruzione era formulata come una condizione singola “o” e il modello non l’ha estesa alla combinazione di entrambe.
La versione corretta avrebbe dovuto essere esplicita: “se l’utente esprime insoddisfazione, o richiede informazioni riservate, o entrambe le cose”. Una piccola aggiunta, una differenza di comportamento significativa. E questo è solo il caso più semplice: gli stessi problemi emergono nelle condizioni negative, nelle eccezioni, nelle regole che si applicano “in tutti i casi tranne”, ovunque, cioè, ci sia una logica che il redattore dava per scontata e che il modello non può inferire.
Un buon sistema di istruzioni non si valuta su quanto funziona nei casi previsti. Si valuta su quanto funziona in quelli che nessuno aveva pensato di specificare.
Le risposte dell’agente rimodellano la conversazione: il problema del contesto azzerato
C’è poi un effetto collaterale delle istruzioni scritte male che è particolarmente insidioso, perché non si manifesta nella singola risposta sbagliata, ma nel modo in cui quella risposta cambia il filo dell’intera conversazione.
Vediamo queste conversazioni:
Cosa è cambiato tra la prima e la seconda conversazione? Il problema non è che l’agente nella prima conversazione abbia dimenticato il contesto, tecnicamente era ancora lì. Il problema è che la prima risposta, che indicava una incapacità di rispondere sul tema, ha funzionato come un reset implicito: ha segnalato al modello che quella richiesta era chiusa, e la conversazione successiva è partita come se fosse nuova.
Formulando la risposta diversamente, “Non ho trovato quello che cercavi, puoi riformulare la domanda?”, il contesto invece rimane attivo. L’utente riformula la domanda, l’agente collega la nuova richiesta a quella precedente, e il Prodotto Blu rimane il soggetto implicito della conversazione.
Non è un dettaglio tecnico marginale. È capire che ciò che entra nella memoria dell’agente, opera come un ulteriore layer di istruzioni e modella attivamente il contesto. In questo caso, quindi, le parole che l’agente usa per gestire l’incertezza non sono neutre: rimodellano attivamente il contesto in cui opera.
Ogni risposta dell’agente entra nel contesto e contribuisce al set di istruzioni.
Il vocabolario aziendale non è universale
C’è un ultimo livello su cui il linguaggio fa la differenza, e riguarda non le istruzioni in sé ma i termini che le istruzioni usano. Ogni organizzazione ha il suo lessico interno — categorie, processi, status, ruoli — che per chi lavora in azienda hanno un significato preciso e condiviso, ma che un modello addestrato su testi generici può interpretare in modo diverso, o semplicemente non definito.
Un esempio concreto:
Un agente viene configurato per trattare in modo prioritario le richieste dei “clienti senior”. Per il team interno, “senior” significa clienti con contratto da oltre tre anni e fatturato sopra una certa soglia. Per il modello, “senior” può indicare anzianità, importanza gerarchica, o niente di specifico. Il risultato è un agente che applica la priorità in modo incoerente, seguendo criteri che nessuno aveva inteso.
La soluzione non è “spiegare” il termine una volta nel testo delle istruzioni. È costruire un glossario operativo che faccia parte integrante della configurazione dell’agente, con definizioni non ambigue e misurabili. Non cliente senior = cliente importante, ma cliente senior = account con contratto attivo da almeno 36 mesi o con volume annuo superiore a una soglia definita.
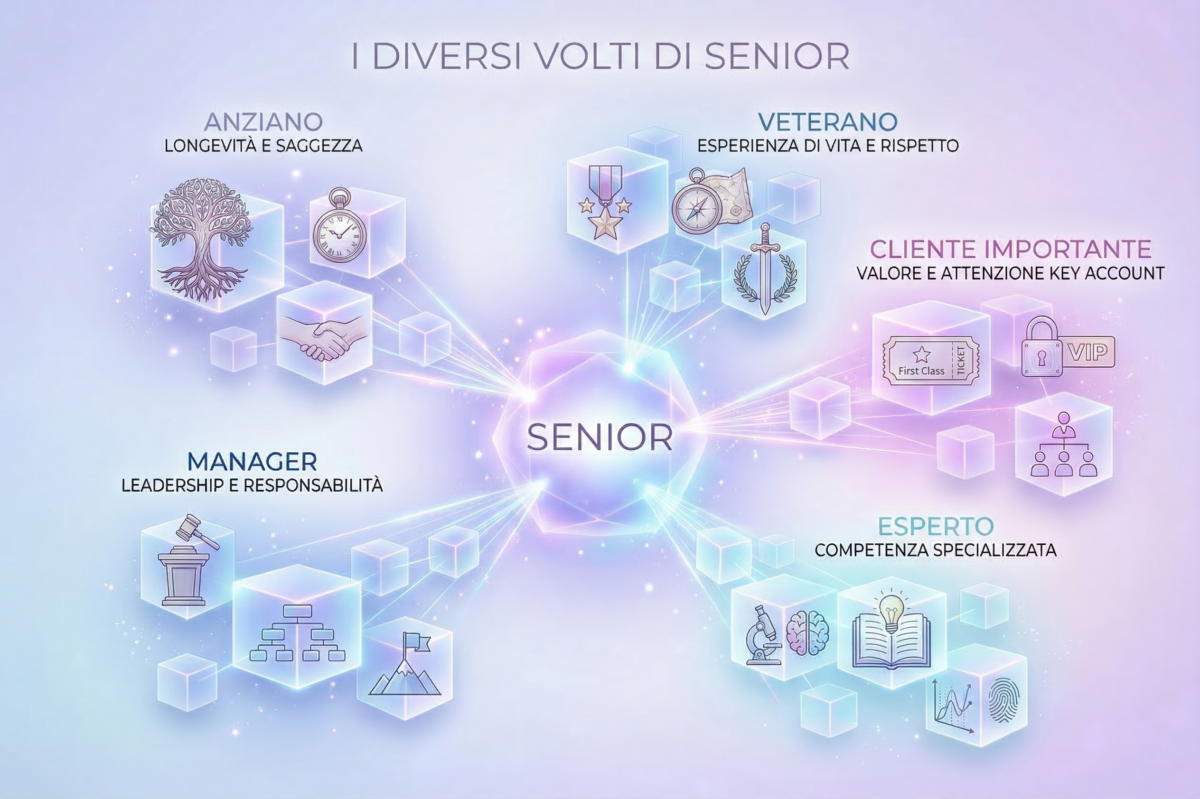
Questo vale ancora di più per i termini che sembrano ovvi come “urgente”, “standard”, “nuovo cliente”, “caso semplice”. Proprio perché sembrano ovvi, raramente vengono definiti. E proprio per questo generano i comportamenti più difficili da diagnosticare: l’agente non sbaglia in modo plateale, sbaglia in modo sottile, applicando una definizione che è solo leggermente diversa da quella attesa.
Cinque atteggiamenti per comunicare meglio con un LLM
Tutto quello che abbiamo visto non richiede competenze tecniche avanzate. Richiede invece un cambio di prospettiva: smettere di scrivere per un interlocutore che capisce le intenzioni, e iniziare a scrivere per uno che capisce solo le parole.
Immaginate di dare istruzioni a un bambino di quattro anni.
I bambini piccoli non hanno pregiudizi né preconoscenze di contesto, bensì interpretano le istruzioni alla lettera, con una logica impeccabile e zero inferenze implicite.
Se dici “puoi vedere la televisione dopo aver mangiato”, il bambino prende una merendina e torna a reclamare la televisione. Non ha torto: ha mangiato. Il problema era nell’istruzione, che intendeva “dopo pranzo” ma non lo aveva detto.
Con un LLM funziona esattamente così.
Tenere presente questo mentre si scrive: pensare come un LLM, o come un bambino di quattro anni, è forse il consiglio più utile che si possa dare. Gli altri cinque discendono da lì.
- Pesa le parole, non solo il senso. Ogni termine porta con sé una sfumatura: “deve” e “dovrebbe” non sono sinonimi, “cliente” e “utente” potrebbero non esserlo nel tuo contesto.
- Non dare niente per ovvio. Tutto quello che non è scritto, non esiste. Se un’informazione è rilevante per il comportamento dell’agente, va scritta. Se una categoria va applicata a certi casi, va detto esplicitamente quali sono quei casi.
- Scrivi per i casi che non hai previsto, non solo per quelli che hai in mente. Le istruzioni nascono quasi sempre da scenari tipici. Ma gli agenti si trovano ad affrontare soprattutto quelli atipici: le combinazioni, le eccezioni, le richieste ibride.
- Evita istruzioni vaghe. Costruzioni linguistiche come “gestisci opportunamente”, “rispondi in modo adeguato”, “valuta caso per caso” non comunicano nulla di operativo al modello.
- Rileggi come se non sapessi nulla. Se nel leggere emergono ambiguità, vuoti, o interpretazioni alternative, il modello le troverà certamente prima e per lui saranno regole operative.
La cura con cui si parla, non la tecnica con cui si programma
Chi decide di adottare un agente AI in azienda di solito pensa alle sfide in termini di integrazione, sicurezza, governance dei dati. Sono sfide reali. Ma c’è una sfida altrettanto reale che riceve meno attenzione, anche perché non sembra una sfida tecnologica: la qualità del linguaggio con cui l’agente viene istruito.
I segnali che qualcosa non va a questo livello sono spesso sottili. L’agente funziona bene nell’80% o più dei casi. I casi problematici sembrano casuali, difficili da riprodurre in modo sistematico. Le correzioni risolvono un comportamento e ne aprono un altro. Se riconosci questo pattern, è molto probabile che il problema non sia nel modello, ma in come gli è stato detto cosa fare.
Non serve essere ingegneri per affrontarlo. Serve un cambio di prospettiva: smettere di dare per scontato che l’agente sappia cosa si intende, e iniziare a scrivere come se dovesse capire tutto dalla sola lettura delle parole. Come si fa con un bambino piccolo, con pazienza e precisione sapendo che lui eseguirà esattamente quello che gli hai detto, e che la responsabilità di dirlo bene è la tua.
La differenza tra un agente che “ci siamo quasi” e uno che funziona davvero passa quasi sempre da qui: non da una scelta tecnologica, ma dalla cura con cui sono state scelte le parole.



