Come abbiamo imparato, che dividere i documenti in blocchi non è un dettaglio tecnico, ma una scelta che determina la qualità di ogni risposta del sistema RAG.
Quando abbiamo costruito il nostro primo sistema RAG, eravamo convinti che la parte difficile fosse il modello linguistico. Il chunking, cioè come dividere i documenti sorgente in blocchi prima di indicizzarli, sembrava una formalità. “Taglia a 500 caratteri e vai”, ci dicevamo.
Qualche mese di produzione ci ha convinti del contrario. La qualità delle risposte che un sistema RAG produce dipende in modo diretto da come i documenti vengono spezzati: chunk troppo piccoli perdono il contesto, chunk troppo grandi introducono rumore. Un PDF tagliato a metà frase restituisce risposte incomprensibili. Una tabella Excel frammentata diventa inutilizzabile. E nessuno di questi problemi è visibile finché non si guarda il comportamento del sistema su casi reali.
Questo articolo racconta come abbiamo affrontato il problema, le soluzioni che abbiamo adottato, i parametri che teniamo sotto controllo, e le lezioni che abbiamo imparato nel tempo. Non è una guida teorica: è quello che facciamo ogni giorno in produzione.
Il punto di partenza: non esiste un chunking universale
La prima cosa da tenere presente è che trattare tutti i documenti allo stesso modo è il sistema più rapido per ottenere risultati mediocri su tutti. Un contratto in PDF ha una struttura completamente diversa da un file JSON con dati strutturati. Un articolo in Markdown con tabelle e immagini non è semplicemente “testo da dividere”. Un foglio Excel non può essere frammentato senza logica.
Abbiamo quindi costruito un sistema di ingestion che riconosce il tipo di documento e applica una strategia di chunking specifica. Oggi gestiamo sei strategie diverse, ognuna ottimizzata per un formato. Non è la soluzione definitiva, continuiamo a iterare, ma è una base molto più solida del “taglia ovunque” con cui eravamo partiti.
Il chunking giusto non è quello più elegante tecnicamente. È quello che preserva il significato che l’utente cercherà quando farà una domanda.
I diversi tipi di documento: quale chunking e quali parametri?
1. PDF e documenti testuali
Quelli che a prima vista sono semplici testi, in realtà camuffano uno scoglio che sembra insormontabile: documenti densi, paragrafi lunghi, a volte tabelle e figure nel mezzo. Il taglio fisso, chiaramente, spezzava le frasi a metà e le risposte erano incomprensibili.
La soluzione che abbiamo adottato si chiama Sentence Window Retrieval: dividiamo per frasi complete, e attorno a ogni chunk manteniamo una finestra di contesto (sei frasi, tre prima e tre dopo). Questo garantisce che nessun chunk sia mai una frase monca e che il modello abbia sempre abbastanza contesto per rispondere in modo coerente. Abbiamo aumentato la finestra da tre a sei frasi nel gennaio 2025, e la differenza sulla qualità del retrieval è stata immediata!
- Are sunbeds and umbrellas subject to charges? No, there is no charge for the pool area sunbeds and umbrellas.
- Is the swimming pool area only open in high season? The swimming pool area is open from May to the end of September, with different times depending on the season.
- Are the swimming pools heated? No.
- Is the use of bathing cap mandatory? Yes. It is mandatory to wear a cap, both for adults and children. If you have forgotten it, they can be purchased at pool bar.
- Which are the swimming pool area opening hours? The swimming pool area is open continuously from approximately 10:00 AM to 6:00 PM. Hours may vary depending on seasonality. In case of bad weather, the area may remain closed.
Prendiamo ad esempio il testo riportato qui sopra, un semplicissimo documento di FAQ.
La finestra di contesto permette alle frasi compiute evidenziate in giallo di avere un contesto adeguato in cui inserirle. Senza la finestra di contesto, infatti, sarebbero frasi semanticamente prive di significato o con un significato parziale.
2. Il formato markdown
Il formato markdown con la sua formattazione di tabelle e immagini ci ha insegnato che “è solo testo” è una semplificazione pericolosa. Le tabelle spezzate a metà diventano incomprensibili; le immagini, se non trattate separatamente, spariscono.
Abbiamo, quindi, costruito un chunker specifico per Markdown che identifica ed estrae le tabelle come chunk autonomi, preserva gli URL delle immagini nei metadata, e divide il testo rimanente per frasi. È più complesso da mantenere, ma molto efficace. Ci permette, infatti, di trattare documenti ricchi senza perdere informazioni.
**\#PRICELIST\_EXTRA\_SERVICE**
**\*\*Questions\*\***
1. **How much does a service cost?**
2. **I need information about services' costs**
3. **Can you provide me with the price list?**
**\*\*Response\*\***
| SERVICE | PRICE | MORE INFO |
|—————|—————|—————————–|
| SWIMMING CAP | € 2,50 | To buy at pool bar |
| TOWELS SET | € 12,00 | One big towel and one small |
| WASHING MACHINE | € 5,00 | To pay in Euro coins, in the machine. Soap not provided |
| DRYER | € 5,00 | To pay by credit/debit card, at machine |
| SUNBEDS AND UMBRELLA | € 25,00 \- € 35,00 | The price is for 2 sunbeds and 1 umbrella for an entire day at bathing beach Lido. 35€ is the price in the first line, 25€ from the third row. Service subject on availability. |
| BUFFET BREAKFAST | € 15,00 | per person per day |
| SHUTTLE BUS | € 2,00 | per person, one way |
| WiFi | € 1,00 (1 h) € 3,00 (24h) € 7,00 (3 days / 3 giorni) € 10,00 (7 days / 7giorni) | One code is for 2 devices at the same time. |
In questo esempio vediamo come il testo è stato nettamente diviso tra la parte puramente testuale e la parte tabellare.
3. JSON e dati strutturati
Con i json o i dati strutturati non lavoriamo per frasi ma per token: chunk da 1000 token ciascuno, senza sovrapposizione. La scelta di zero overlap è deliberata: per dati strutturati, la prevedibilità sui costi di embedding e la pulizia della struttura contano più della continuità tra chunk adiacenti. I metadata compensano la potenziale perdita di contesto, tracciando ogni chunk al documento e alla posizione originale.
4. Gli intenti (Q&A)
I Q&A configurati dai clienti (domande e risposte precise che definiscono come il bot deve rispondere a certi input) vengono gestiti in modo diverso a seconda del tipo. I casi di corrispondenza esatta o per parole chiave vengono risolti fuori dal sistema RAG con delle logiche di stemming.
Nel caso della similitudine invece, dove entra in gioco l’analisi semantica, raggruppiamo le diverse frasi di esempio dell’input con la risposta. Quindi indicizziamo ogni intento (Q&A) come chunk indipendente e lo confrontiamo singolarmente con la domanda utente.
5. Excel
Infine, Excel: ogni riga conta. Suddividiamo l’intero foglio in righe. La logica è semplice: la chiave, in ogni tabella, è la combinazione di ogni riga con l’intestazione di ogni colonna. Ecco perché facciamo un chunking per riga + intestazione.
| Name | Typology | Description | Cost |
| Product 1 | Base | Product 1 is a product for requirement number 1. | 1€ |
| Product 2 | Base | Product 2 is a product for requirement number 2. | 2€ |
| Product 3 | Advanced | Product 3 is a product for requirement number 3. | 3€ |
In questo caso, per esempio, avremo tre chunk in output così composti:
| Name: Product 1 | Typology: Base | Description: Product 1 is a product for requirement number 1. | Cost: 1€ |
| Name: Product 2 | Typology: Base | Description: Product 2 is a product for requirement number 2. | Cost: 2€ |
| Name: Product 3 | Typology: Advanced | Description: Product 3 is a product for requirement number 3. | Cost: 3€ |
6. I casi speciali
Ovviamente le cinque tipologie di formato non coprono tutti casi. Per ora, quindi, per formati proprietari o non standard, abbiamo infine una strategia configurabile: un delimitatore personalizzato — per esempio un simbolo specifico come “|” — che permette di adattare il chunking a qualsiasi formato che i clienti potrebbero portare nel sistema.
Definire la strategia per tipo di documento è solo il primo livello del percorso.
Il bello dei parametri è che non sono scolpiti nella pietra. Li possiamo integrare e migliorare continuamente sulla base dei feedback reali degli utenti .
I trade-off che abbiamo imparato
Come abbiamo visto, ogni scelta di chunking è un compromesso. Non esiste la configurazione ottimale in assoluto, ma esiste quella più adatta al caso d’uso specifico. Avere chiarezza sui trade-off che si stanno accettando è il modo per prendere decisioni consapevoli e prevenire e mitigare le conseguenze in produzione.
Chunk più piccoli migliorano la precisione del retrieval ma aumentano i costi di embedding e riducono il contesto disponibile.
Chunk più grandi preservano più contesto semantico ma introducono rumore e rallentano il sistema. Per esempio, la finestra di sei frasi che usiamo per i documenti testuali (PDF, word, txt) è un equilibrio deliberato tra questi due estremi.
Stesso discorso per lo zero overlap sui JSON, un’altra scelta consapevole. Sappiamo che al confine tra due chunk consecutivi può esserci perdita di contesto. Abbiamo accettato questo rischio perché per dati strutturati la prevedibilità e l’efficienza contano più della continuità narrativa.
Come vedremo nel prossimo paragrafo, i metadata, che tracciano ogni chunk alla sua posizione nel documento originale, mitigano parzialmente il problema.
I metadata: la parte invisibile che tiene tutto insieme
Ogni chunk non è un’entità isolata: porta con sé un set di informazioni che permettono di tracciarlo, contestualizzarlo e, quando qualcosa va storto, diagnosticarlo. Sono proprio i metadati.
Nel nostro sistema, ogni chunk contiene diversi metadati:
- gli identificatori del documento originale,
- gli identificatori del flusso e del bot a cui appartiene;
- il contesto delle frasi adiacenti (in base al tipo di documento);
- il tipo di contenuto (testo, tabella, immagine).
Queste informazioni vengono aggiunte prima del chunking e preservate durante tutto il processo di embedding e retrieval.
Sembra un dettaglio implementativo. In realtà è quello che rende il sistema governabile. Senza metadata, quando un agente restituisce una risposta sarebbe impossibile risalire a quale chunk l’ha generata, da quale documento proveniva, e perché è stato recuperato. Con metadata ricchi, queste informazioni sono sempre recuperabili e permettono di agire sull’agente con governance e trasparenza.
Nella nostra piattaforma, infatti, è possibile mostrare sia sulla chat di conversazione che nella parte di analisi, quali sono le fonti utilizzate dall’agente per rispondere e i singoli chunk recuperati dal RAG.

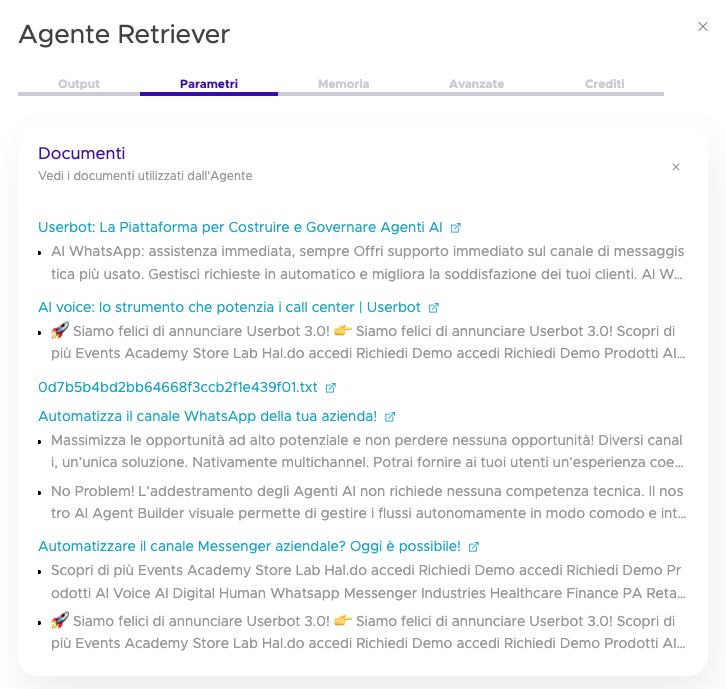
Un chunk senza metadata è come una citazione senza fonte: manca di trasparenza. Puoi usarla, ma non puoi verificarla, correggerla, né capire perché è lì.
Le lezioni che abbiamo imparato e che vogliamo condividere
Guardando indietro all’evoluzione del nostro sistema, ci piace l’idea di aver imparato tanto. Ecco le nostre “lessons learned”:
La lezione più importante è che il chunking è una decisione architettonica, non un parametro di configurazione. Cambiare la dimensione dei chunk o la strategia di overlap dopo che il sistema è in produzione non è un aggiustamento: è una migrazione. Richiede di re-indicizzare tutto, di riverificare il comportamento del retrieval, di testare nuovamente i casi limite. Il valore di questa decisione è immenso e vale la pena investire all’inizio in fase di analisi.
La seconda lezione è che la qualità del chunking non si vede nei test. Si vede quando un utente reale pone una domanda che nessuno aveva previsto e il sistema non riesce a rispondere; non perché l’informazione non ci sia, ma perché il chunk che la contiene è stato tagliato nel posto sbagliato. I test controllati non coprono mai abbastanza la varietà del linguaggio naturale in produzione.
La terza — e forse la più controintuitiva — è che migliorare il chunking spesso vale più che migliorare il modello. Un sistema RAG con chunking ottimizzato e un modello buono performa meglio di un sistema con chunking approssimativo e un modello eccellente. La qualità dell’output dipende dalla qualità dell’input che arriva al modello, e quella dipende dal chunking.
Iterare sul chunking è probabilmente l’intervento con il miglior rapporto tra sforzo e impatto in un sistema RAG maturo. È meno visibile che cambiare modello, ma quasi sempre più efficace.
Una decisione che vale la pena fare bene
Chi commissiona o supervisiona un sistema RAG raramente ha motivo di entrare nel dettaglio del chunking.
Il processo di chunking, infatti, non è una manopola che può essere regolata a piacere dal cliente o da chi implementa il progetto. È una decisione architetturale, che richiede competenze specifiche e che impatta tutto il prodotto. È una scelta tecnica, delegata al team che costruisce il sistema.
Ma è utile sapere che quella scelta esiste, che ha un impatto diretto sulla qualità delle risposte, e che “funziona” nei test non è necessariamente la stessa cosa che “funziona” in produzione.
La chiave quindi sono le domande giuste da farsi, quando si valuta o si supervisiona un sistema RAG:
- come vengono trattati i diversi tipi di documento?
- su quali parametri si è iterato, e perché?
- quando il sistema sbaglia, è possibile risalire al chunk che ha generato l’errore?
Se il team ha risposte chiare a queste domande, è probabile che il chunking sia stato affrontato con la serietà che merita. Se le risposte sono vaghe, vale la pena approfondire.
Non è tutto oro quel che luccica e, anche noi, abbiamo speso mesi di analisi e parecchi errori per arrivare a un sistema che consideriamo robusto. Non è perfetto — continuiamo a iterare — ma è costruito su scelte consapevoli, parametrizzate e documentate. Ed è esattamente da lì che, nella nostra esperienza, si parte per costruire un sistema RAG che funziona davvero. Considerato che è infatti una scelta strutturale e spesso irreversibile nel breve periodo, è una decisione che vale la pena fare bene.