



Nel post su Context Engineering abbiamo introdotto la memoria come uno dei quattro building block fondamentali per gestire il contesto di un agente AI. Abbiamo distinto tra working memory, memoria semantica e memoria episodica, abbastanza per capire il quadro generale. Ma “abbastanza per capire il quadro” non è sufficiente per costruire un Agente AI affidabile in produzione.
In questo articolo andiamo più a fondo. Come funziona la memoria di un agente? Come l’abbiamo implementata su Userbot? E soprattutto: cosa può andare storto quando la memoria cresce troppo o viene usata male?
Breve termine vs lungo termine
Prima di entrare nei dettagli tecnici, vale la pena chiarire una distinzione fondamentale nella progettazione di agenti.
Memoria a breve termine (short-term memory)
La memoria a breve termine (short-term memory) è quella che l’agente può vedere durante una singola inferenza.
Vive dentro la finestra di contesto (context window) e contiene:
- il system prompt,
- la cronologia della conversazione,
- i risultati dei tool invocati,
- i chunk recuperati dal RAG.
Ma attenzione, è temporanea: sparisce quando la sessione termina o smette di aggiornarsi quando si raggiunge il limite di token della finestra di contesto.
Memoria a lungo termine (long-term memory)
La memoria a lungo termine è tutto ciò che deve sopravvivere oltre la conversazione corrente:
- informazioni sull’utente,
- stato di processi precedenti,
- dati storici.
Per la sua natura non può stare sempre nella context window: viene archiviata esternamente e reiniettata nel contesto solo quando serve.
Memoria a breve termine: come funziona la context window
La working memory di un agente è strutturata intorno alla context window del modello. In ogni chiamata, il modello riceve una fotografia del contesto corrente: le istruzioni di sistema, la conversazione fino a quel punto, eventuali risultati di tool o documenti recuperati. È volatile per definizione e non persiste tra una sessione/conversazione e l’altra.
Una pratica comune, che abbiamo menzionato nell’articolo precedente, è includere gli ultimi N messaggi della conversazione.
Funziona.
Fino a un certo punto.
Il problema è che i modelli non leggono il contesto in modo uniforme. Ricercatori hanno documentato questo comportamento nel paper “Lost in the Middle“: le performance degradano sistematicamente quando l’informazione rilevante si trova nella parte centrale di un contesto lungo, mentre tendono a essere migliori quando quella stessa informazione è posizionata all’inizio o alla fine della finestra di contesto. Il risultato è che aggiungere messaggi non garantisce che il modello li usi, e spesso non li usa nel modo atteso.
Questo non significa che la working memory sia inutile, è indispensabile.
Significa che va gestita attivamente: non basta aggiungere messaggi, bisogna scegliere la quantità e che tipi di messaggi aggiungono davvero valore al contesto e quali no.
Come Userbot gestisce la memoria degli Agenti AI
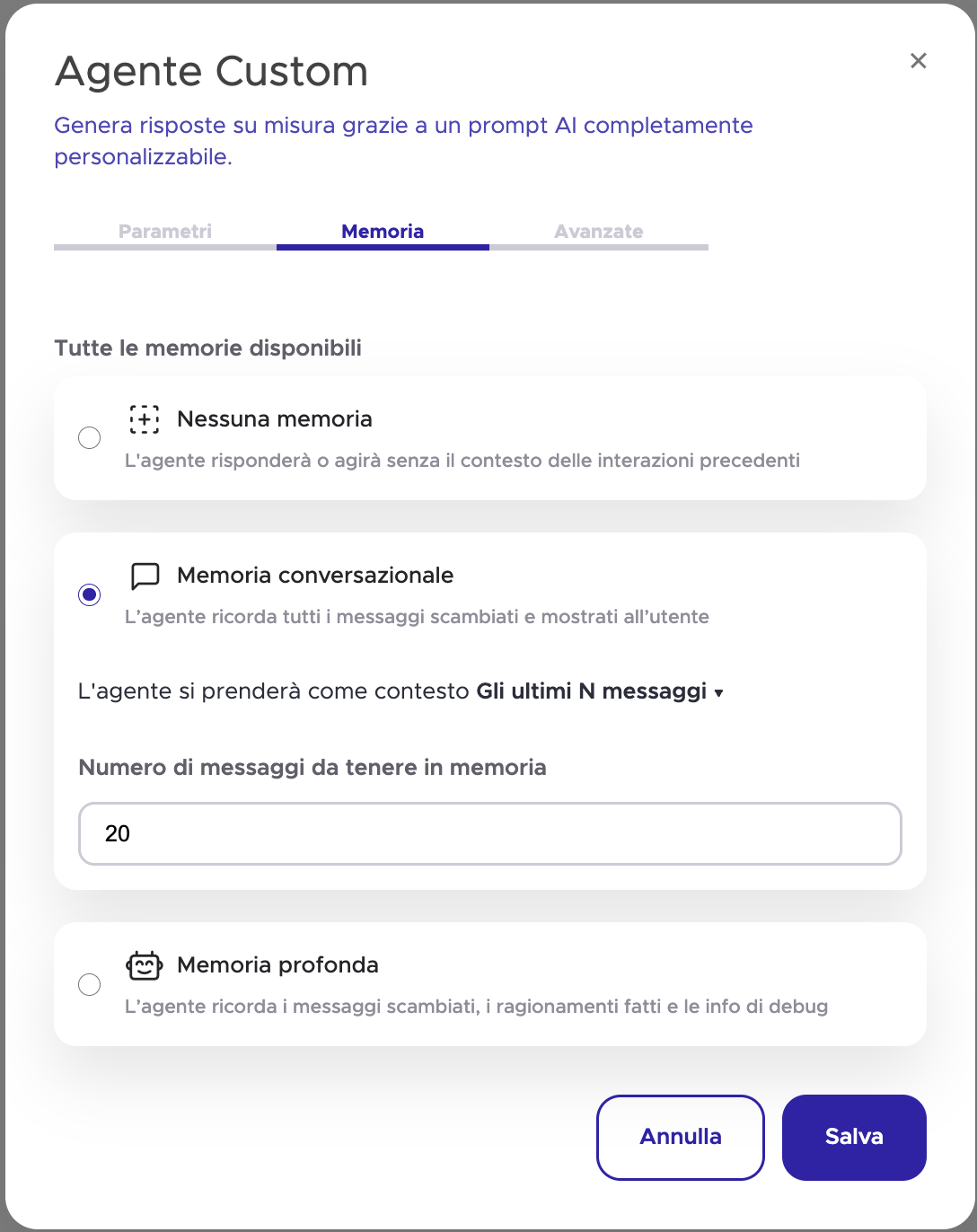
Nella configurazione di un Agente su Userbot, la tab Memoria espone tre modalità operative che corrispondono a tre scelte architetturali precise.
No Memory è la modalità più semplice: l’agente risponde senza alcun accesso al contesto di interazioni precedenti. Ogni messaggio viene trattato come se fosse l’unico. È la scelta giusta per task completamente isolati, dove il contesto pregresso non è rilevante o potrebbe addirittura introdurre rumore.

Esempio:
Un agente di rilevamento PII analizza ogni messaggio in ingresso per identificare la presenza di dati personali sensibili, come codice fiscale, numero di telefono o indirizzo email. Il suo output è binario, true quando viene rilevato un dato sensibile (e si innescano le azioni successive) oppure false quando il messaggio è pulito e il flusso prosegue normalmente. Non ha bisogno di sapere cosa ha scritto l'utente nei messaggi precedenti, perché ogni testo è un'unità di analisi indipendente. Portare in contesto la cronologia della conversazione non aggiungerebbe nulla alla rilevazione e aumenterebbe solo il rischio di interferenza.
Conversation Memory è la modalità predefinita: l’agente ricorda i messaggi scambiati nella conversazione corrente, e puoi configurare quanti messaggi mantenere in memoria. Il default è 20. Come vedremo nella sezione sui rischi, questo numero non è arbitrario: la scelta di N ha conseguenze dirette sulla qualità delle risposte. In Userbot viene selezionata come scelta predefinita e corrisponde a una short-memory standard.
Esempio:
Un agente di supporto gestisce l'apertura di un ticket in modo conversazionale. L'utente descrive il problema, l'agente fa domande di chiarimento nel corso di più turni: qual è il dispositivo coinvolto, da quando si verifica il problema, se ci sono stati cambiamenti recenti. Alla fine chiama il tool di creazione ticket con tutti i dati raccolti. Senza memoria di conversazione, chiederebbe le stesse informazioni a ogni messaggio. Con la cronologia disponibile, costruisce il contesto progressivamente e sa esattamente a che punto è il processo.
Deep Memory aggiunge un livello ulteriore: oltre ai messaggi scambiati con l’utente, l’agente memorizza il proprio ragionamento interno e le informazioni di debugging tra i vari blocchi del flusso. È la modalità più ricca di contesto, pensata per scenari complessi dove capire come l’agente è arrivato a una certa risposta è tanto importante quanto la risposta stessa. Utile in fase di sviluppo e testing, o in workflow dove la tracciabilità del processo decisionale è un requisito. La nota negativa di questa modalità sono l’introduzione di rumore e l’aumento dei token di contesto.
Esempio:
In un workflow Agentico di qualificazione commerciale, un primo agente conversazionale raccoglie le informazioni iniziali dal potenziale cliente: settore, dimensione aziendale, problema che vuole risolvere. Con la Deep Memory attiva, passa al secondo agente non solo le risposte dell'utente, ma anche il proprio ragionamento: perché ha classificato il lead come qualificato, quali segnali ha rilevato nella conversazione, quali obiezioni sono già emerse. Il secondo agente, specializzato nella proposta commerciale, riceve un contesto completo e costruisce una risposta mirata senza dover rielaborare da zero le informazioni già raccolte.
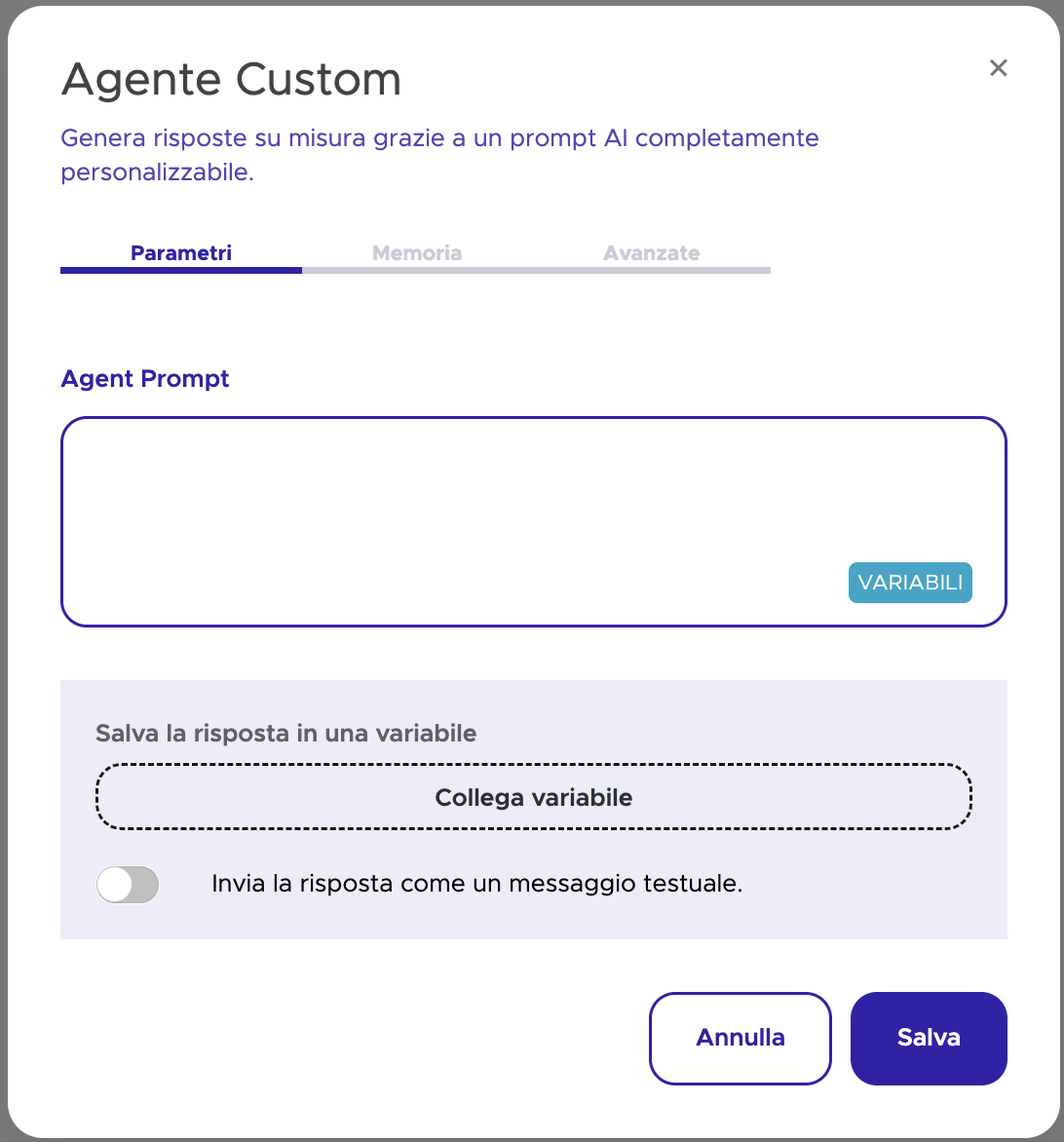
Vale la pena notare che la configurazione della memoria non è separata dalla configurazione del prompt: il campo Agent Prompt nella tab Parametri definisce le istruzioni di sistema che vengono combinate con la memoria selezionata a ogni inferenza. La qualità della working memory, infatti, dipende da entrambi: da quanti messaggi includi e da come hai strutturato le istruzioni che li accompagnano.
Rischi nascosti della memoria negli Agenti AI
Più memoria non equivale automaticamente a un agente migliore. In alcuni scenari, una memoria mal gestita produce errori ambigui e difficili da diagnosticare rispetto a un agente senza memoria.
Allucinazioni da contesto lungo
Il rischio più documentato è l’aumento delle allucinazioni all’aumentare della lunghezza del contesto. Quando la conversation history cresce, il modello non elabora ogni token con la stessa attenzione. Tende a mescolare informazioni provenienti da punti diversi della conversazione, a confondere contesti simili o a generare risposte che sembrano coerenti con la memoria ma non lo sono.
Uso errato dei tool
Un secondo rischio, meno ovvio ma ugualmente rilevante, riguarda il comportamento dell’agente nella scelta e nell’uso dei tool. In conversazioni lunghe, il modello tende a “implicare” le risposte dalla memoria invece di invocare il tool corretto per recuperare informazioni aggiornate.
Il meccanismo è questo: il modello trova nella cronologia della conversazione una risposta plausibile a una domanda simile a quella attuale, e la usa, anche quando quella risposta è obsoleta oppure quando si riferisce a un contesto diverso. Non è un errore intenzionale: è una conseguenza di come i modelli bilanciano il costo computazionale tra generazione diretta e tool use.
Risposte implicite da memoria
Connessa al punto precedente, c’è la tendenza del modello a formulare risposte per analogia con interazioni passate, bypassando il ragionamento esplicito. Se un utente ha posto una domanda simile tre iterazioni prima, e quella domanda ha ricevuto una risposta specifica, l’agente può usare quel precedente come shortcut anche quando la situazione attuale richiede una risposta diversa.
Il problema non è tanto la risposta sbagliata, è che l’errore è difficile da rilevare, perché la risposta è coerente con la memoria anche se non è corretta per il contesto attuale. Più la memoria è ricca, più questo rischio è elevato.
Best practice: come tenere la memoria sotto controllo
- La prima pratica è calibrare il numero di messaggi (N). Su Userbot il default di 20 messaggi per la Memoria Conversazionale è un punto di partenza ragionevole, ma non è una risposta universale. Per conversazioni brevi e transazionali come apertura di ticket, prenotazioni oppure FAQ, 10 messaggi possono essere più che sufficienti. Per conversazioni complesse e multi-turno, potrebbero esserne necessari anche più di 20. La regola pratica è: includi solo i messaggi che aggiungono contesto utile, non quelli che aggiungono lunghezza.
- La seconda pratica è separare i tipi di memoria. E’ opportuno non mescolare informazioni fisse (profilo utente, preferenze) con informazioni transitorie (cronologia della conversazione corrente) nella stessa struttura.
- La terza pratica è preferire tool call esplicite a recuperi impliciti dalla memoria per informazioni critiche. Se lo stato di un ordine, il saldo di un account o la disponibilità di un prodotto devono essere accurati, l’agente deve chiamare il tool, non fare inferenza dalla cronologia. Questo può essere imposto esplicitamente nel system prompt, ma richiede anche che il tool sia progettato per essere chiamato frequentemente senza costi eccessivi.
- La quarta pratica è usare la Deep Memory con criterio. Il fatto che la Memoria Profonda memorizzi ragionamento e debugging la rende potente in fase di sviluppo, ma quella stessa ricchezza aumenta la lunghezza del contesto e conseguentemente il rischio di interferenza. In produzione, la Conversation Memory è spesso la scelta più stabile.
Memoria agentica: il fattore che determina affidabilità in produzione
La memoria è un aspetto spesso sottovalutato nella progettazione di agenti AI. Non perché sia difficile da implementare, su Userbot bastano tre click. Ma perché le sue conseguenze, quando mal configurata, emergono lentamente e in modo non ovvio: risposte leggermente sbagliate, tool invocati con parametri errati, comportamenti che si degradano nel tempo. Conoscere la memoria di un agente, nei meccanismi e nei limiti, è quello che separa una demo da un sistema affidabile in produzione.
possiamo aiutarti?
il nostro team è a tua disposizione.




