

AI in produzione non è il momento in cui un Agente AI inizia a rispondere bene. È il momento in cui ci accorgiamo che deve continuare a farlo anche quando il sistema sotto cambia.
L’Agente AI è live, serve utenti reali, i processi iniziano a dipendere da lui. Poi qualcosa si muove nell’infrastruttura, come un modello LLM viene aggiornato, sostituito o ritirato, e il comportamento che avevamo validato non è più garantito.
Sulla carta è un upgrade. Nella pratica, quando rilanciamo i test sul golden dataset, scopri che alcune risposte sono migliori, altre peggiori, altre semplicemente diverse. E la cosa più destabilizzante è che spesso non è immediato spiegare perché.
Non è un’anomalia. È una proprietà strutturale dei sistemi basati su modelli generativi. E se si sta costruendo agenti AI che automatizzano processi reali (non demo, non PoC!) vale la pena trattarla con la stessa serietà con cui tratteremmo una migrazione di database o un cambio di provider infrastrutturale.
Perché i golden dataset danno risultati diversi
Partiamo da una verità poco glamour: un modello linguistico non è una funzione deterministica. Anche a parità di input, piccoli cambiamenti nel decoding, nella gestione del contesto, o nei filtri di sicurezza possono produrre output diversi. E quando parliamo di sistemi agentici, l’output non dipende solo dal modello: dipende dall’intero sistema.
In produzione, un Agente moderno raramente è “solo chat”. È più simile a una pipeline:
- recupero di contesto (knowledge base, documenti, pagine web, con RAG),
- regole e policy (cosa è consentito dire e come),
- strumenti (API, webhook, azioni su CRM/ERP/ticketing),
- orchestrazione tra componenti (routing, specializzazione di agenti, escalation all’umano).
Se cambia uno di questi pezzi, il comportamento complessivo può cambiare, anche se l’applicazione “non è stata toccata”. Il golden dataset, di conseguenza, non misura più un modello: misura un’implementazione storica di un sistema.
Questo è il punto chiave: il drift non è solo del modello. È anche drift del contesto.
Il contratto implicito: non compri un modello, compri un comportamento
Nel mondo software, abbiamo imparato a ragionare per contratti: API stabili, semantic versioning, backward compatibility. Con l’AI generativa spesso facciamo l’opposto: trattiamo il modello come una dipendenza esterna e speriamo che resti più o meno uguale.
Ma in produzione non ci interessa che il modello sia il migliore in assoluto. Ci interessa che rispetti un comportamento utile e sicuro: risposte coerenti con la knowledge base, stile e tono consistenti, affidabilità su intenti critici, gestione corretta delle eccezioni, e soprattutto una qualità che non regredisce senza che ce ne accorgiamo.
In pratica serve rendere esplicito il contratto che oggi è implicito. E quel contratto va testato, osservato e governato.
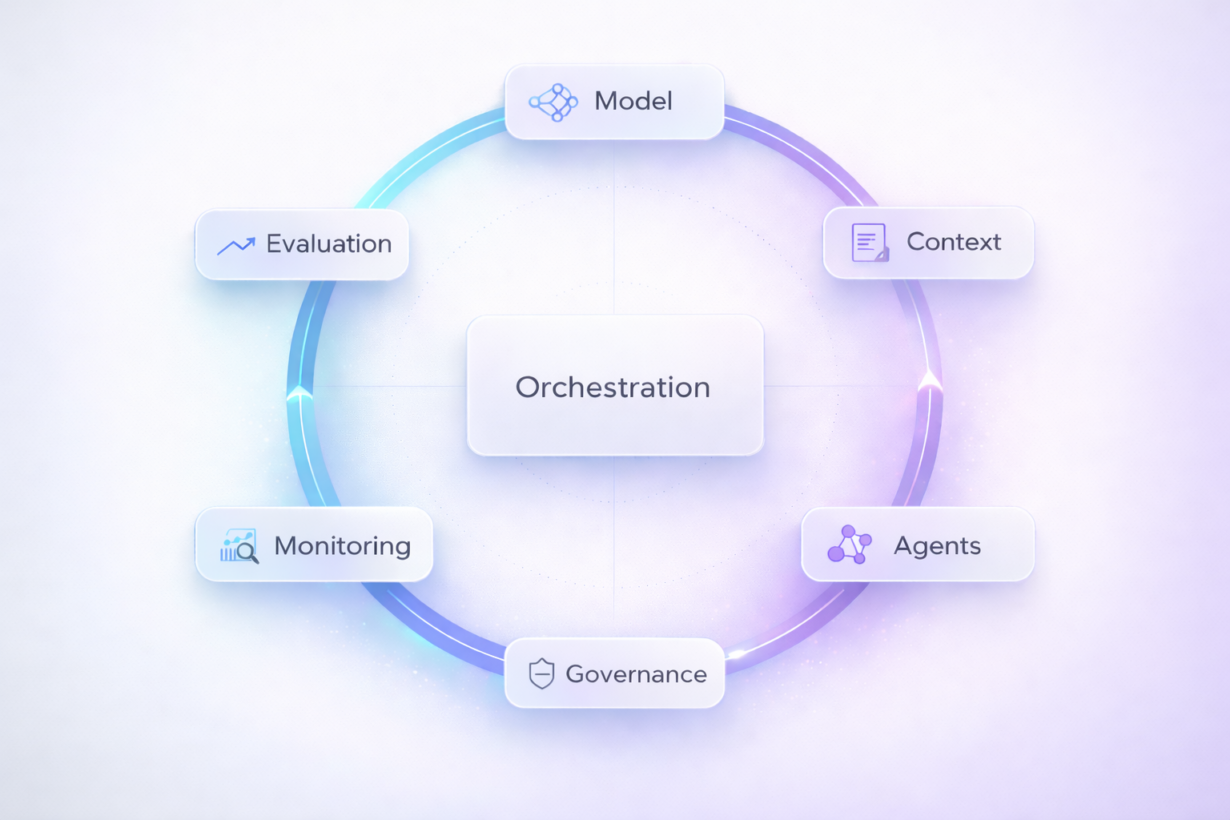
La disciplina che fa la differenza: LLMOps per agenti
La tentazione è aumentare i test. Ma “più test” non bastano se non cambia il tipo di test.
Un golden dataset classico (domanda → risposta attesa) funziona bene quando la risposta è quasi deterministica. Con i modelli generativi, invece, spesso la risposta corretta non è una stringa, ma una famiglia di risposte accettabili che rispettano vincoli: correttezza fattuale rispetto alla knowledge base, completezza, tono, assenza di allucinazioni, corretta chiamata degli strumenti quando necessaria.
Qui entra la disciplina che sta emergendo in tutte le aziende che portano agenti AI in produzione: un insieme di pratiche che assomiglia a MLOps, ma è più vicino all’ingegneria dei sistemi. Alcuni elementi sono ormai imprescindibili:
- Evals continui, non solo a progetto finito: test di regressione su intenti, rubriche qualitative, metriche su tool-use e fallimenti.
- Rollout controllati: prima shadow mode (valutazioni senza impatto), poi canary su una percentuale di traffico, poi espansione.
- Osservabilità: non solo log di conversazione, ma segnali su costi, latenza, tassi di escalation, errori di retrieval, drift di distribuzione delle richieste.
- Incident management: quando qualcosa “non torna”, serve un modo ripetibile per capire cosa è cambiato (modello, prompt, knowledge base, tool, policy) e ripristinare.
Questa è la differenza tra “usare un LLM” e “operare un sistema AI”.
Progettare per il cambiamento: model lifecycle management
Se accettiamo che i modelli cambiano (per evoluzione, aggiornamenti di sicurezza, ritiro o sostituzione) la domanda diventa: come progettare un prodotto che non si rompa ogni volta che il motore sotto cambia?
Un approccio pratico è separare ciò che deve essere stabile da ciò che è lecito che evolva.
Stabile dovrebbe essere il contratto di comportamento: cosa l’agente deve fare, quali fonti deve usare, quali azioni può eseguire, quando deve scalare su umano, quali errori sono accettabili e quali no. Evolutivo può essere il modo in cui ottieni quel comportamento: modello A oggi, modello B domani, routing dinamico, fallback, versioni multiple in parallelo.
In architettura, questo si traduce in un principio semplice: astrarre i modelli dietro una piattaforma o un layer di orchestrazione. Così l’applicazione non dipende più da GPT-X, ma da un’interfaccia comportamentale governata, osservata e testata.
Dove una piattaforma di orchestrazione aiuta davvero
Quando l’AI entra in produzione, la complessità non sparisce. Si sposta. La scelta è se farla ricadere sul fornitore o sul team del cliente (che deve inseguire upgrade, ritiri, regressioni, logging, policy, integrazioni) oppure incorporarla in una piattaforma pensata per governare agenti nel tempo.
Userbot ha proprio quest’obiettivo, fornisce un’unica piattaforma per costruire, orchestrare e governare un team di agenti AI, con percorsi guidati, dashboard per supervisionare e ottimizzare, e integrazioni con sistemi aziendali via API/webhook, oltre a gestire la sicurezza, GDPR e trasparenza sul processo decisionale.
Questo tipo di approccio ha un vantaggio poco visibile nelle demo, ma enorme in produzione: permette di trattare il cambio modello come un evento gestibile, non come una crisi. Se il sistema è costruito con osservabilità, test e rollout controllati, l’upgrade diventa un’operazione ingegneristica con guardrail, non un salto nel buio.
AI in produzione significa progettare per l’evoluzione
I modelli continueranno a cambiare. È nella natura stessa dell’AI moderna: evoluzione continua, miglioramenti, nuovi trade-off. Aspettarsi stabilità assoluta da un sistema probabilistico è come montare un motore diverso su un’auto e pretendere che consumi, risposta dell’acceleratore e comportamento su strada restino identici al millimetro. L’auto è sempre “quella”, ma la dinamica cambia e va ricalibrata.
La vera domanda, quindi, non è “quale modello usi?” ma “quanto sei attrezzato per gestire il cambiamento?”
È qui che si vede la differenza tra chi parla di AI e chi la opera in produzione.
Nel mondo delle demo, il focus è sulle capability: quanto ragiona il modello, quanto è fluido il linguaggio, quanto impressiona la risposta. Nel mondo reale, invece, contano altre cose: cosa succede quando il comportamento cambia, come intercetti una regressione prima che impatti gli utenti, come governi sicurezza, qualità, costi e continuità operativa mentre l’infrastruttura sotto evolve.
Portare l’AI in produzione significa accettare che il modello non è un componente statico ma una dipendenza viva. Significa progettare sistemi che non si limitano a funzionare oggi, ma che restano affidabili mentre tutto intorno si muove. Significa avere osservabilità, eval continui, rollout controllati, policy e fallback: non come accessori, ma come parte dell’architettura.
È esattamente questa esperienza operativa che distingue un progetto AI sperimentale da un sistema che regge carichi reali, utenti reali e processi aziendali reali. E, in fondo, è qui che si gioca la maturità di un’organizzazione: non nella capacità di accendere un modello, ma in quella di governarlo nel tempo.